- База данных Фирма
- Руководство по разработке структуры и проектированию базы данных
- Этапы создания базы данных
- Анализ требований: определение цели базы данных
- Структура базы данных: построение блоков
- Создание связей между сущностями
- Связь «один-к одному»
- Связь «один-ко-многим»
- Связь «многие-ко-многим»
- Обязательно или нет?
- Рекурсивные связи
- Лишние связи
- Нормализация базы данных
- Первая форма нормализации
- Вторая форма нормализации
- Третья форма нормализации
- Многомерные данные
- Правила целостности данных
- Добавление индексов и представлений
- Расширенные свойства
- SQL и UML
- Системы управления базами данных
База данных Фирма
Чтобы создать новую базу данных в среде « MS Access 2002» нужно запустить программу, перейти в главное меню и выбрать «Файл – Создать… – Новая база данных».
Далее необходимо создать набор таблиц базы данных, пусть это будут: Сотрудники, Отделы, Должности, Зарплаты. Чтобы их сделать нужно перейти в раздел «Таблицы» и выбрать один из вариантов, например, «Создание таблицы в режиме конструктора».
Таблица 1. Таблицы базы данных «Фирма» и типы данных полей
ID_Сотрудника : Ключ, Счетчик
Фамилия: Текстовый, 20
Имя: Текстовый, 20
Отчество: Текстовый, 20
Телефон, Текстовый, 11
Домашний адрес, Текстовый, 50
ID_Отдела , Длинное целое
ID_Должности : Длинное целое, Внешний ключ
ID_Отдела : Ключ, Счетчик
Название: Текстовый, 20
Город: Текстовый, 20
Телефон: Текстовый, 11
ID_Должности : Ключ, Счетчик
Название: Текстовый, 20
Размер ставки: Действительное
ID_Зарплаты : Длинное целое, Внешний ключ
ID_Зарплаты : Ключ, Счетчик
Кроме того, поля с внешними ключами лучше сделать при помощи мастера подстановок.
Когда таблицы будут созданы, их надо их связать между собой создав схему данных. Делается она вызывание из главного меню «Сервис – Схема данных». Запустив ее, первым делом надо выбрать набор таблиц, с которыми будем производить связывание. Связи осуществляются путем перетаскивание мышкой связываемого поля. Хотя если перед этим прошлись по базе и внешним ключам, то нужно всего лишь изменить связи, т.е. расставить галочки на каскадное удаление и обеспечение целостности данных.
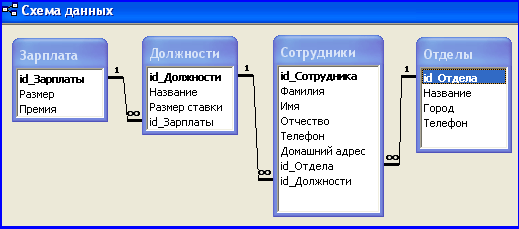
Рис. 1. Схема данных базы «Фирма»
Также, для удобства и для выявления ошибок неплохо бы частично заполнить таблицы базы данных.

Рис. 2. Таблица «Зарплата»

Рис. 3. Таблица «Должности»

Рис. 4. Таблица «Отделы»

Рис. 5. Таблица «Сотрудники»
Далее нужно сделать несколько полезных запросов, для этого переходим в раздел «Запросы». Кстати, запросы можно создавать двумя путями: с помощью мастера и при помощи конструктора.
Если создавать запрос с помощью мастера, то сначала будет предложено выбрать необходимые поля из таблиц, затем определиться с типом представления данных и в конце надо задать имя запроса.
Если создавать запрос при помощи конструктора, то в начале опять же выбираем таблицы к которым будем обращаться, затем поля, можно также установить сортировку, группировку и условия отбора. Также в конструкторе можно изменить названия столбцов.
В СУБД « MS Access » существуют следующие типы запросов:
Например, если есть необходимость создать запрос на обновление данных в таблице «Зарплата», то нужно запустить конструктор запросов, выбрать таблицу «Зарплата», затем выбрать обновляемые поля и наконец тип запроса – на обновление. Далее в поле «Обновление» необходимо вписать или построить выражение для изменения поля.

Рис. 6. Построение запроса на изменение зарплаты и премии
В данном конкретном случае показан запрос на индексацию зарплат и премий на +10%. Ниже показан результат проведенной индексации, т.е. все зарплаты и премии сотрудников увеличились на заданный размер.

Рис. 7. Результат выполнения запроса на обновление записей таблицы «Зарплата»
Также в СУБД « MS Access 2002» можно создавать различные формы, опять же или в режиме конструктора, или в режиме мастера. Формы можно создавать как по таблицам, та и по запросам.
Если создавать форму с помощью мастера, то в начале будет предложено выбрать необходимые поля из имеющихся таблиц. Затем надо определиться с внешним видом формы. Далее выбрать стиль отчета. И, наконец, задать имя отчета.
В режиме конструктора создавать новые отчеты несколько дольше, чем мастером. Поэтому удобней создавать отчеты мастером, а уж потом если есть такая необходимость изменять их в режиме конструктора.
Для создания отчета нужно перейти в раздел «Отчеты», запустить мастер, выбрать необходимые поля из таблиц. Например, если создавать отчет по зарплате сотрудников, то можно выбрать из таблицы «Сотрудники» поля: Фамилия, Имя, Отчество. А из таблицы «Зарплата» поля: Размер, Премия. Потом мастер предложит выбрать вид представления данных, затем уровни группировки. Также мастер предложит отсортировать записи. Затем надо выбрать макет отчета и стиль. И, наконец, надо задать имя отчета.

Рис. 8. Отчет «Сотрудники и их зарплата»
Также для удобства навигации можно создать главную кнопочную форму базы «Фирма», которая будет открываться при запуске файла с базой данных, что довольно удобно.

Рис. 9. Главная кнопочная форма базы данных
Источник
Руководство по разработке структуры и проектированию базы данных
Следуя принципам, описанным в этой статье, можно создать базу данных, которая работает надлежащим образом и в будущем может быть адаптирована под новые требования. Мы рассмотрим основные принципы проектирования базы данных , а также способы ее оптимизации.
Этапы создания базы данных
Надлежащим образом структурированная база данных:
- Помогает сэкономить дисковое пространство за счет исключения лишних данных;
- Поддерживает точность и целостность данных;
- Обеспечивает удобный доступ к данным.
Основные этапы разработки базы данных:
- Анализ требований или определение цели базы данных;
- Организация данных в таблицах;
- Указание первичных ключей и анализ связей;
- Нормализация таблиц.
Рассмотрим каждый этап проектирования баз данных подробнее. Обратите внимание, что в этом руководстве рассматривается реляционная модель базы данных Эдгара Кодда , написанная на языке SQL ( а не иерархическая, сетевая или объектная модели ).
Анализ требований: определение цели базы данных
Например, если вы создаете базу данных для публичной библиотеки, нужно продумать, каким образом и читатели, и библиотекари должны получать доступ к БД .
Вот несколько способов сбора информации перед созданием базы данных:
- Опрос людей, которые будут ее использовать;
- Анализ бизнес-форм, таких как счета-фактуры, расписания, опросы;
- Рассмотрение всех существующих систем данных ( включая физические и цифровые файлы ).
Начните со сбора существующих данных, которые будут включены в базу. Затем определите типы данных, которые нужно сохранить. А также объекты, которые описывают эти данные. Например:
- Имя;
- Адрес;
- Город, штат, почтовый индекс;
- Адрес электронной почты.
- Название;
- Цена;
- Количество в наличии;
- Количество под заказ.
- Номер заказа;
- Торговый представитель;
- Дата;
- Товар;
- Количество;
- Цена;
- Стоимость.
При проектировании реляционной базы данных эта информация позже станет частью словаря данных, в котором описаны таблицы и поля БД . Разбейте информацию на минимально возможные части. Например, подумайте о том, чтобы разделить поле почтового адреса и штата, чтобы можно было фильтровать людей по штату, в котором они проживают.
После того, как вы определились с тем, какие данные будут включены в базу, откуда эти данные будут поступать, и как они будут использоваться, можно приступить к планированию фактической БД .
Структура базы данных: построение блоков
Следующим шагом будет визуальное представление базы данных. Для этого нужно точно знать, как структурируются реляционные БД . Внутри базы связанные данные группируются в таблицы, каждая из которых состоит из строк и столбцов.
Чтобы преобразовать списки данных в таблицы, начните с создания таблицы для каждого типа объектов, таких как товары, продажи, клиенты и заказы. Вот пример:
Каждая строка таблицы называется записью. Записи включают в себя информацию о чем-то или о ком-то, например, о конкретном клиенте. Столбцы (также называемые полями или атрибутами) содержат информацию одного типа, которая отображается для каждой записи, например, адреса всех клиентов, перечисленных в таблице.

- CHAR — конкретная длина текста;
- VARCHAR — текст различной длины;
- TEXT — большой объем текста;
- INT — положительное или отрицательное целое число;
- FLOAT , DOUBLE — числа с плавающей запятой;
- BLOB — двоичные данные.
Некоторые СУБД также предлагают тип данных Autonumber , который автоматически генерирует уникальный номер в каждой строке.
В визуальном представлении БД каждая таблица будет представлена блоком на диаграмме. В заголовке каждого блока должно быть указано, что описывают данные в этой таблице, а ниже должны быть перечислены атрибуты:

Атрибуты, выбранные в качестве первичных ключей, должны быть уникальными, неизменяемыми и для них не может быть задано значение NULL ( они не могут быть пустыми ). По этой причине номера заказов и имена пользователей являются подходящими первичными ключами, а номера телефонов или адреса — нет. Также можно использовать в качестве первичного ключа несколько полей одновременно ( это называется составным ключом ).
Когда придет время создавать фактическую БД , вы реализуете как логическую, так и физическую структуру через язык определения данных, поддерживаемый вашей СУБД .
Также необходимо оценить размер БД , чтобы убедиться, что можно получить требуемый уровень производительности и у вас достаточно места для хранения данных.
Создание связей между сущностями
Теперь, когда данные преобразованы в таблицы, нужно проанализировать связи между ними. Сложность базы данных определяется количеством элементов, взаимодействующих между двумя связанными таблицами. Определение сложности помогает убедиться, что вы разделили данные на таблицы наиболее эффективно.
Каждый объект может быть взаимосвязан с другим с помощью одного из трех типов связи:
Связь «один-к одному»
Когда существует только один экземпляр объекта A для каждого экземпляра объекта B, говорят, что между ними существует связь « один-к одному » ( часто обозначается 1:1 ). Можно указать этот тип связи в ER-диаграмме линией с тире на каждом конце:

Но при определенных обстоятельствах целесообразнее создавать таблицы со связями 1:1 . Если есть поле с необязательными данными, например «описание», которое не заполнено для многих записей, можно переместить все описания в отдельную таблицу, исключая пустые поля и улучшая производительность базы данных.
Чтобы гарантировать, что данные соотносятся правильно, в нужно будет включить, по крайней мере, один идентичный столбец в каждой таблице. Скорее всего, это будет первичный ключ.
Связь «один-ко-многим»
Эта связи возникают, когда запись в одной таблице связана с несколькими записями в другой. Например, один клиент мог разместить много заказов, или у читателя может быть сразу несколько книг, взятых в библиотеке. Связи « один- ко-многим » ( 1:M ) обозначаются так называемой «меткой ноги вороны», как в этом примере:

Связь «многие-ко-многим»
Когда несколько объектов таблицы могут быть связаны с несколькими объектами другой. Говорят, что они имеют связь « многие-ко-многим » ( M:N ). Например, в случае студентов и курсов, поскольку студент может посещать много курсов, и каждый курс могут посещать много студентов.
На ER-диаграмме эти связи отображаются с помощью следующих строк:

Для этого нужно создать между этими двумя таблицами новую сущность. Если между продажами и продуктами существует связь M:N , можно назвать этот новый объект « sold_products », так как он будет содержать данные для каждой продажи. И таблица продаж, и таблица товаров будут иметь связь 1:M с sold_products . Этот вид промежуточного объекта в различных моделях называется таблицей ссылок, ассоциативным объектом или таблицей связей.
Каждая запись в таблице связей будет соответствовать двум сущностям из соседних таблиц. Например, таблица связей между студентами и курсами может выглядеть следующим образом:

Обязательно или нет?
Другим способом анализа связей является рассмотрение того, какая сторона связи должна существовать, чтобы существовала другая. Необязательная сторона может быть отмечена кружком на линии. Например, страна должна существовать для того, чтобы иметь представителя в Организации Объединенных Наций, а не наоборот:

Рекурсивные связи
Иногда при проектировании базы данных таблица указывает на себя саму. Например, таблица сотрудников может иметь атрибут «руководитель», который ссылается на другое лицо в этой же таблице. Это называется рекурсивными связями.
Лишние связи
Лишние связи — это те, которые выражены более одного раза. Как правило, можно удалить одну из таких связей без потери какой-либо важной информации. Например, если объект « ученики » имеет прямую связь с другим объектом, называемым « учителя », но также имеет косвенные отношения с учителями через « предметы », нужно удалить связь между « учениками » и « учителями ». Так как единственный способ, которым ученикам назначают учителей — это предметы.
Нормализация базы данных
После предварительного проектирования базы данных можно применить правила нормализации, чтобы убедиться, что таблицы структурированы правильно.
В то же время не все базы данных необходимо нормализовать. В целом, базы с обработкой транзакций в реальном времени ( OLTP ), должны быть нормализованы.
Базы данных с интерактивной аналитической обработкой ( OLAP ), позволяющие проще и быстрее выполнять анализ данных, могут быть более эффективными с определенной степенью денормализации. Основным критерием здесь является скорость вычислений. Каждая форма или уровень нормализации включает правила, связанные с нижними формами.
Первая форма нормализации
Первая форма нормализации ( сокращенно 1NF ) гласит, что во время логического проектирования базы данных каждая ячейка в таблице может иметь только одно значение, а не список значений. Поэтому таблица, подобная той, которая приведена ниже, не соответствует 1NF :


Вторая форма нормализации
Вторая форма нормализации ( 2NF ) предусматривает, что каждый из атрибутов должен полностью зависеть от первичного ключа. Каждый атрибут должен напрямую зависеть от всего первичного ключа, а не косвенно через другой атрибут.
Например, атрибут « возраст » зависит от « дня рождения », который, в свою очередь, зависит от « ID студента », имеет частичную функциональную зависимость. Таблица, содержащая эти атрибуты, не будет соответствовать второй форме нормализации.
Кроме этого таблица с первичным ключом, состоящим из нескольких полей, нарушает вторую форму нормализации, если одно или несколько полей не зависят от каждой части ключа.
Таким образом, таблица с этими полями не будет соответствовать второй форме нормализации, поскольку атрибут « название товара » зависит от идентификатора продукта, но не от номера заказа:
- Номер заказа ( первичный ключ );
- ID товара ( первичный ключ );
- Название товара.
Третья форма нормализации
Третья форма нормализации ( 3NF ) : каждый не ключевой столбец должен быть независим от любого другого столбца. Если при проектировании реляционной базы данных изменение значения в одном не ключевом столбце вызывает изменение другого значения, эта таблица не соответствует третьей форме нормализации.
В соответствии с 3NF , нельзя хранить в таблице любые производные данные, такие как столбец « Налог », который в приведенном ниже примере, напрямую зависит от общей стоимости заказа:

Многомерные данные
Некоторым пользователям может потребоваться доступ к нескольким разрезам одного типа данных, особенно в базах данных OLAP. Например, им может потребоваться узнать продажи по клиенту, стране и месяцу. В этой ситуации лучше создать центральную таблицу, на которую могут ссылаться таблицы клиентов, стран и месяцев. Например:

Правила целостности данных
Также с помощью средств проектирования баз данных необходимо настроить БД с учетом возможности проверки данных на соответствие определенным правилам. Многие СУБД , такие как Microsoft Access , автоматически применяют некоторые из этих правил.
Правило целостности гласит, что первичный ключ никогда не может быть равен NULL . Если ключ состоит из нескольких столбцов, ни один из них не может быть равен NULL . В противном случае он может неоднозначно идентифицировать запись.
Правило целостности ссылок требует, чтобы каждый внешний ключ, указанный в одной таблице, сопоставлялся с одним первичным ключом в таблице, на которую он ссылается. Если первичный ключ изменяется или удаляется, эти изменения необходимо реализовать во всех объектах, на которые ссылается этот ключ в базе данных.
Правила целостности бизнес-логики обеспечивают соответствие данных определенным логическим параметрам. Например, время встречи должно быть в пределах стандартных рабочих часов.
Добавление индексов и представлений
Индекс — это отсортированная копия одного или нескольких столбцов со значениями в возрастающем или убывающем порядке. Добавление индекса позволяет быстрее находить записи. Вместо повторной сортировки для каждого запроса система может обращаться к записям в порядке, указанном индексом.
Хотя индексы ускоряют извлечение данных, они могут замедлять добавление, обновление и удаление данных, поскольку индекс нужно перестраивать всякий раз, когда изменяется запись.
Представление — это сохраненный запрос данных. Представления могут включать в себя данные из нескольких таблиц или отображать часть таблицы.
Расширенные свойства
После того как схема базы данных будет готова можно уточнить БД с помощью расширенных свойств, таких как справочный текст, маски ввода и правила форматирования, которые применяются к конкретной схеме, представлению или столбцу. Преимущество этого метода заключается в том, что, поскольку эти правила хранятся в самой базе, представление данных будет согласовано между несколькими программами, которые обращаются к данным.
SQL и UML
Унифицированный язык моделирования ( UML ) — это еще один визуальный способ выражения сложных систем, созданных на объектно-ориентированном языке. Некоторые из концепций, упомянутых в этом руководстве, известны в UML под разными названиями. Например, объект в UML известен, как класс.
Сейчас UML используется не так часто. В наши дни он применяется академически и в общении между разработчиками программного обеспечения и их клиентами.
Системы управления базами данных
Проектируемая структура базы данных зависит от того, какую СУБД вы используете. Некоторые из наиболее распространенных:
- Oracle DB ;
- MySQL ;
- Microsoft SQL Server ;
- PostgreSQL ;
- IBM DB2 .
Подходящую систему управления базами данных можно выбирать исходя из стоимости, установленной операционной системы, наличия различных функций и т. д.
Источник