Распределение доходностей на рынке акций
Автор: Дмитрий Никитенко
Дата записи
Сегодня мы разберем очень интересную тему о распределении доходностей акций. Она раскрывает природу инвестиционного риска ещё глубже и позволяет лучше понять как именно работает фондовый рынок и чего от него следует ожидать.
Если вы ещё не читали статью про инвестиционный риск, стоит сначала прочитать в ней про стандартное отклонение.
Распределение доходностей на фондовых рынках принято сравнивать с кривой нормального распределения (по функции Гаусса). Хотя далее мы выясним, что реальное распределение доходностей не полностью соответствует этой кривой, она весьма неплохо описывает происходящее на рынке на длинных периодах времени.
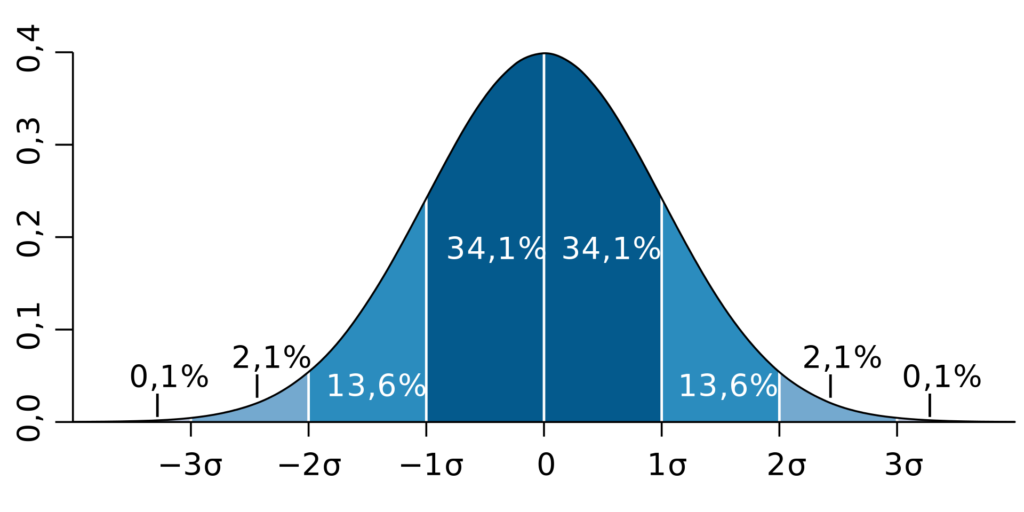 Кривая нормального распределения. По оси X – стандартное отклонение, по оси Y – вероятность. Проценты – это частота попадания значения стандартного отклонения в закрашенную область под кривой. Источник: Википедия
Кривая нормального распределения. По оси X – стандартное отклонение, по оси Y – вероятность. Проценты – это частота попадания значения стандартного отклонения в закрашенную область под кривой. Источник: Википедия
Смысл нормального распределения заключается в том, что основная часть значений случайной величины концентрируется возле своей средней (математического ожидания случайной величины), а значения по краям кривой маловероятны (случаются редко). Так, чем больше стандартное отклонение значений от среднего, тем меньше вероятность их появления.
В статистике существует правило трёх сигм (стандартных отклонений), которое наглядно изображено на графике выше. Закрашенные на нём области под кривой показывают сколько процентов времени стандартное отклонение значений случайной величины не превышает одну, две или три сигмы. Значения с отклонением более трёх сигм считаются практически невозможными.
Чтобы проверить соблюдается ли нормальное распределение доходностей на рынке акций, возьмем полные (с дивидендами) реальные (выше инфляции) доходности акций США на периоде с 1871 по 2018 год (по данным Роберта Шиллера и Yahoo! Finance):
- среднее арифметическое этих доходностей составило 8.5%;
- стандартное отклонение = 18.5%.
Если бы кривая нормального распределения полностью описывала распределение доходностей на фондовом рынке, то, согласно правилу трёх сигм:
- 68.27% времени доходность была бы между средним арифметическим ± одно стандартное отклонение (-10% и 27%);
- 95.45% времени – между средним ± два стандартных отклонения (-28.5% и 45.5%);
- 99.73% времени – между средним ± три стандартных отклонения (-47% и 64%).
Наблюдение за реальными данными даёт хоть и похожий, но всё же отличающийся результат. На самом деле доходности рынка акций США выше инфляции за 148 лет укладывались:
- в одно стандартное отклонение от своей средней арифметической 67.57% времени (не 68.27%);
- в два стандартных отклонения – 93.92% времени (не 95.45%);
- в три стандартных отклонения – 100% времени (не 99.7%), значений за пределами -47% и 64% за этот период не было, минимальная и максимальная доходность составили -38.47% в 1931 году и 57.16% в 1954 году.
Получается, что 9 из 148 лет принесли доходность меньше -28.49% или больше 45.51% (двух стандартных отклонений), что составило 6.08% случаев, а не ожидаемые согласно нормальному распределению 100% — 95.45% = 4.55%. Разница не так велика, но она есть и говорит о том, что аномальные доходности на рынке акций немного более вероятны, чем предсказывает нормальное распределение.
Посмотрим на те же данные по США на графике распределения доходностей. Здесь и далее снова используются полные реальные годовые доходности, разделенные на интервалы по 10%, каждый год определен в свой интервал.
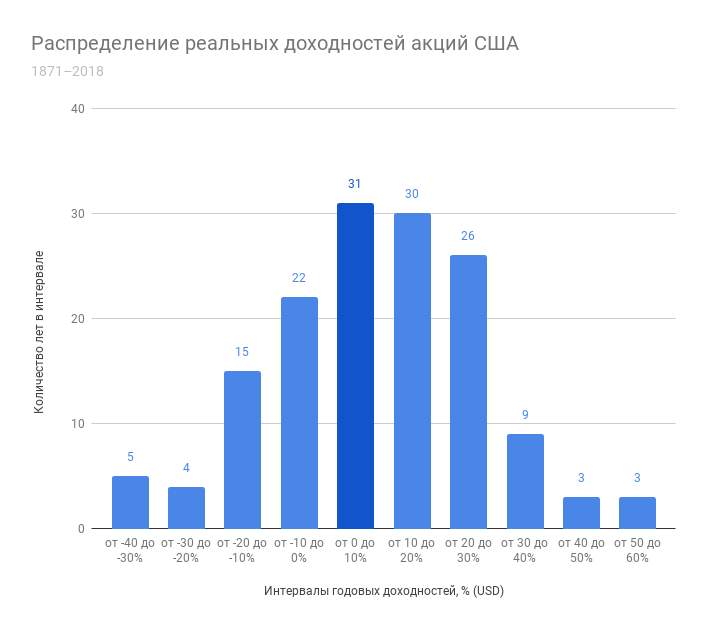 Источники данных: Robert Shiller, Yahoo! Finance; инфляция: Robert Shiller, Bureau of Labor Statistics
Источники данных: Robert Shiller, Yahoo! Finance; инфляция: Robert Shiller, Bureau of Labor Statistics
График напоминает кривую нормального распределения, однако, крайних значений немного больше, чем предполагает гауссиана, а значит они случаются чаще. Интервал от -40 до -30% содержит в себе 5 лет, что больше, чем у предыдущего интервала от -30 до -20% (4 года), а интервал от 50 до 60% содержит в себе столько же лет (3), сколько и предыдущий, хотя согласно нормальному распределению тоже должен быть меньше.
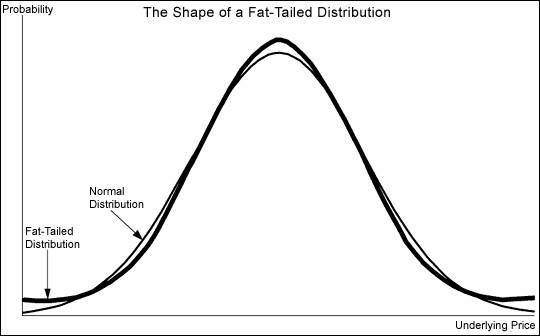
Это называется fat tail или толстый хвост кривой – вместо того, чтобы стремиться к оси абсцисс (к нулю), кривая может отрываться от неё, что не соответствует нормальному распределению. Крупные просадки или аномально высокие доходности не настолько маловероятны как предсказывает гауссиана, что получило название tail risk. Такое поведение рынка подчёркивает важность психологии в инвестировании и умения инвестора пережидать плохие годы, не продавая активы. Каким бы плохим не был отдельно взятый день или год, доходность акций и облигаций имеет положительное математическое ожидание (среднее значение), а значит время и сложный процент сделают своё дело.
Используя индекс полной доходности MSCI World Net я также построил график распределения реальных годовых доходностей акций развитых стран. Хотя доступная выборка по нему значительно меньше (с 1970 года), можно отметить сходство в количестве положительных периодов с акциями США – практически 70% времени он приносил положительную реальную доходность. Об особенностях распределения на этом периоде я говорить не буду – довольно маленькое число наблюдений. Здесь худшим годом для индекса стал 2008 – доходность едва опустилась за -40% с учетом инфляции, а лучшим – 1986 с практически такой же доходностью, но без минуса.
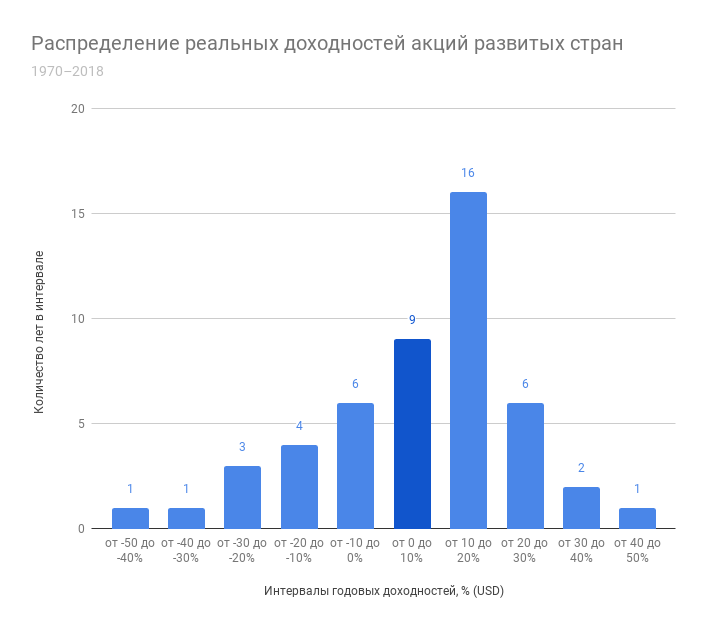 График: Capital-Gain.ru. Источники данных: MSCI World Net Index; инфляция: Bureau of Labor Statistics
График: Capital-Gain.ru. Источники данных: MSCI World Net Index; инфляция: Bureau of Labor Statistics
И, наконец, давайте посмотрим на распределение месячных доходностей на рынке акций США с 1988 года (375 месяцев).
 График: Capital-Gain.ru. Источник данных: Yahoo! Finance
График: Capital-Gain.ru. Источник данных: Yahoo! Finance
Здесь тоже можно заметить аномальные доходности по краям (больше ±10% за один месяц — это сильно). Но что ещё общего можно заметить на этих графиках? Они все немного сдвинуты вправо по оси доходностей, можно сказать, имеют больший вес в своей положительной части. Это является свидетельством того, что доходность акций исторически имела положительное математическое ожидание. По сути мы видим здесь ту добавленную стоимость, что генерирует бизнес по всему миру.
Нассим Николас Талеб в своей книге «Черный лебедь» пишет, что нормальное распределение отлично подходит для описания физически ограниченных значений (например, рост человека), потому что они не масштабируются так сильно, как физически неограниченные (например, продажи бестселлера или доходность фондового рынка). Конечно, ни продажи, ни доходность не могут быть бесконечными, однако, вы с гораздо меньшей вероятностью встретите человека ростом 3 метра, чем неожиданно проданную огромным тиражом книгу или аномальную доходность на рынке. Такие из ряда вон выходящие события он называет черными и белыми лебедями (в зависимости от того негативный оно имеет смысл или позитивный). Тут стоит отметить, что, на мой взгляд и по результатам самостоятельного анализа данных, как нормальное распределение не описывает доходности на фондовом рынке полностью, так и Талеб в своей книге преувеличивает значимость этих отклонений от нормального распределения , если смотреть на них с точки зрения долгосрочного инвестора. Для трейдеров, впрочем, эти отклонения действительно могут быть гораздо более значительными, ведь они оперируют более короткими временными интервалами, на которых аномальные (для правила трёх сигм) доходности случаются чаще – в дневных и месячных данных появляются стандартные отклонения и больше трёх сигм, что по нормальному распределению практически невозможно. К тому же трейдеры могут автоматически фиксировать убытки с помощью биржевых заявок стоп лосс, которые не применяются пассивными портфельными инвесторами.
Популярным примером является черный понедельник 19 октября 1987 года, когда индекс Dow Jones за один день упал на 22.61% – 25 своих дневных стандартных отклонений (!). Более недавний пример, изображенный на графике ниже – 24 июня 2016 года, когда состоялся референдум о Брексите и некоторые активы продемонстрировали аномальную дневную доходность. Количество лет в последней колонке таблицы, которые, согласно нормальному распределению, надо подождать, чтобы увидеть такие дневные доходности, намекает нам, что они гораздо более вероятны, чем может предсказать кривая Гаусса.
 Доходности инструментов в день референдума в Великобритании, их множитель СКО и количество лет, раз в которые они ожидаются согласно нормальному распределению вероятностей. Источник: Charlie Bilello
Доходности инструментов в день референдума в Великобритании, их множитель СКО и количество лет, раз в которые они ожидаются согласно нормальному распределению вероятностей. Источник: Charlie Bilello
Несмотря на то, что аномальные доходности на фондовом рынке – не такая редкость, как может спрогнозировать кривая нормального распределения, долгосрочному инвестору не стоит обращать внимания на них и уж тем более продавать свои активы из-за плохих новостей, фиксируя убыток , потому что такие аномальные доходности встречаются чаще именно на дневных или месячных данных, чем на годовых. Картинка ниже вполне подтверждает выделенные в этой статье утверждения – плохие новости или нет, положительная ожидаемая доходность и сложный процент долгосрочно заставляют капитал расти.
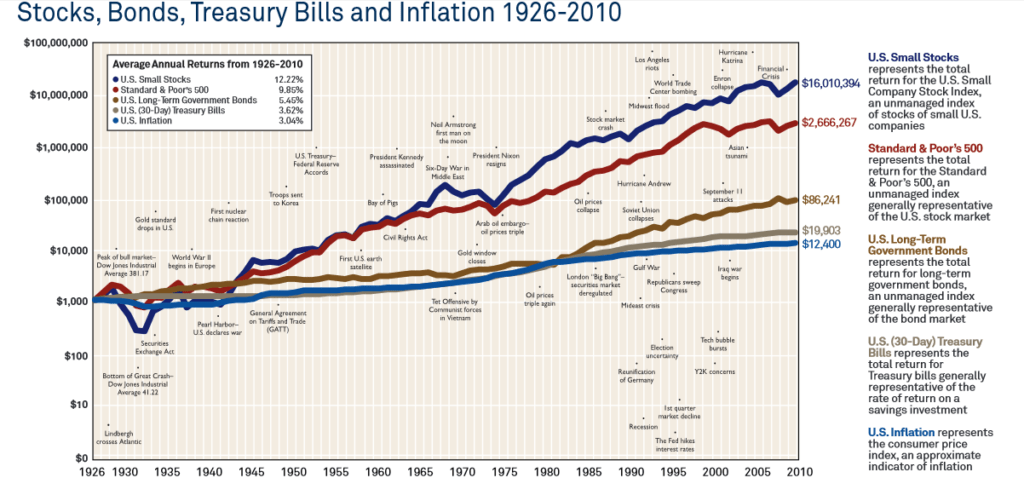 Прирост капитала, вложенного в акции компаний малой капитализации (small stocks), крупной капитализации (large stocks), государственные облигации (government bonds), векселя (treasury bills) и инфляция. Источник: SeekingAlpha
Прирост капитала, вложенного в акции компаний малой капитализации (small stocks), крупной капитализации (large stocks), государственные облигации (government bonds), векселя (treasury bills) и инфляция. Источник: SeekingAlpha
На выше графике показаны события, которые повлияли на рынок. Как видите, несмотря на войны и кризисы, активы показали значимый прирост капитала, опережающий инфляцию. Другой популярный пример против торговли по новостям показывает, как часто СМИ ошибаются в своих прогнозах.
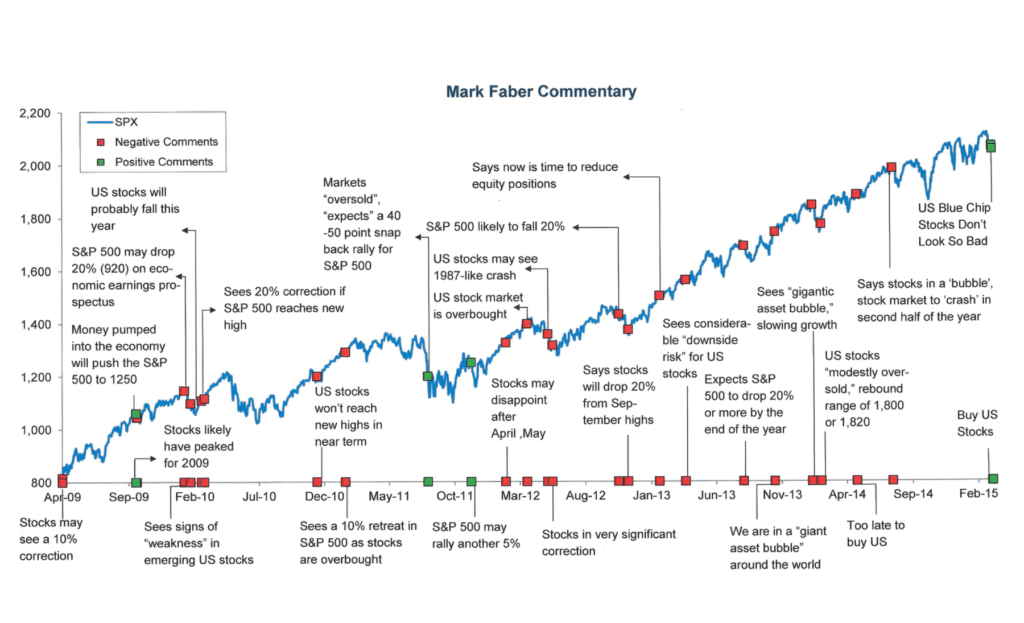 График индекса акций США S&P 500 и новостные заголовки. Источник: Barry Ritholtz
График индекса акций США S&P 500 и новостные заголовки. Источник: Barry Ritholtz
Комиссии и распределение доходностей
На новости мы повлиять не можем, зато вполне возможно повлиять на комиссии и налоги, которые инвестор платит фондам, брокерам и государству. Чем больше размер комиссий и налогов, тем меньше математическое ожидание доходности портфеля, а значит и распределение его доходностей на графике смещается влево на размер комиссий и налогов – ближе к отрицательной зоне. Схематично это показано на графике ниже.
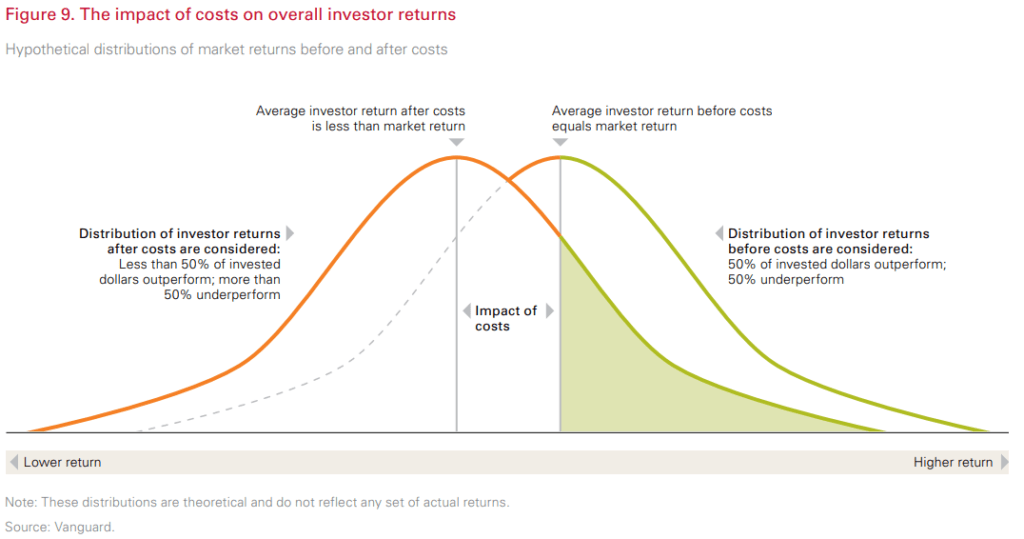 Влияние комиссий и налогов на распределение доходностей. Источник: Vanguard
Влияние комиссий и налогов на распределение доходностей. Источник: Vanguard
Долгосрочному пассивному инвестору гораздо полезнее думать о том как уменьшить свои комиссии и воспользоваться налоговыми льготами, чем о новостях и аномалиях на фондовом рынке.
Источник
CFA — Нормальное распределение вероятностей
Нормальное распределение — это наиболее часто используемое распределение вероятностей в количественной финансовой практике. Оно играет ключевую роль в современной портфельной теории и ряде технологий управления рисками. Рассмотрим эту концепцию в рамках изучения количественных методов по программе CFA.
Поскольку нормальное распределение вероятностей имеет так много применений, профессионалы в области финансов и инвестиций должны тщательно его изучить.
Роль нормального распределения в статистических выводах и регрессионном анализе значительно расширена благодаря центральной предельной теореме. Центральная предельная теорема (англ. ‘central limit theorem’) утверждает, что сумма (и среднее) большого числа независимых случайных величин приблизительно нормально распределена.
Французский математик Абрахам Де Муавр (Abraham de Moivre, 1667-1754) ввел понятие нормального распределения в 1733 году при разработке своей версии центральной предельной теоремы.
Как показано на Рисунке 5, нормальное распределение является симметричным и имеет колоколообразную форму.
Диапазоном возможных исходов нормального распределения является вся вещественная ось: все действительные числа, лежащих между \(-\infty\) и \(+\infty\). Хвосты колоколообразной кривой распространяются без ограничений слева и справа.
Определяющими характеристиками нормального распределения являются:
Нормальное распределение полностью описывается двумя параметрами — ее средним значением, \( \mu \), и дисперсией, \( \sigma^2 \). Обозначим это как \( X \sim N (\mu, \sigma^2) \) (читается «X имеет нормальное распределение со средним \(p\) и дисперсией \(\sigma^2\)» ).
Мы также можем определить нормальное распределение с точки зрения среднего и стандартного отклонения, \( \sigma \) (часто это удобно, так как \( \sigma \) измеряется в тех же единицах, что и \(X\) и \(\mu\)). Как следствие, мы можем ответить на любой вопрос о вероятности нормальной случайной величины, если мы знаем его среднее значение и дисперсию (или стандартное отклонение).
Нормальное распределение имеет асимметрию 0 (симметрично). Нормальное распределение имеет эксцесс (мера крутизны или островершинности распределения) 3; его избыточный эксцесс (эксцесс — 3.0) равен 0.
Если мы имеем выборку размера \(n\) из нормального распределения, мы хотим знать о возможном изменении в асимметрии и эксцессе выборки. Для нормальной случайной величины, стандартное отклонение ассиметрии выборки равно \(6/n\), стандартное отклонение эксцесса выборки равно \( 24/n \).
Как следствие симметрии, среднее, медиана и мода равны для нормальной случайной величины.
Линейная комбинация двух или более нормальных случайных величин также распределена нормально.
Перечисленное выше касается только одной переменной величины или одномерного нормального распределения: распределения одной нормальной случайной величины. Одномерное распределение (англ. ‘univariate distribution’) описывает одну случайную величину.
Многомерное распределение (англ. ‘multivariate distribution’) определяет вероятности для группы связанных случайных величин. Вы столкнетесь с многомерным нормальным распределением (англ. ‘multivariate normal distribution’) в инвестиционной деятельности и должны знать о нем следующее.
Когда мы имеем группу финансовых активов, мы можем моделировать распределение доходности для каждого актива в отдельности, или распределение доходности для активов как для группы. «Как для группы» означает, что мы принимаем во внимание всех статистических взаимосвязей между доходностью активов.
Одна из моделей, которая часто используется для оценки доходности ценных бумаг, является многомерным нормальным распределением. Многомерное нормальное распределение для доходности ценных бумаг полностью определяется этими тремя списками параметров:
- списком средних ставок доходности по отдельным ценным бумагам (всего \(n\) средних всего);
- списком дисперсий доходности ценных бумаг (всего \(n\) дисперсий); а также
- списком всех отчетливых попарных корреляций доходности (всего \(n (n — 1) / 2\) различных корреляций).
Например, распределение для двух акций (двумерное нормальное распределение) имеет 2 средние, 2 дисперсии и 1 корреляцию: \( 2 (2 — 1) / 2\).
Распределение для 30 акций имеет 30 средних, 30 дисперсий и 435 различных корреляций: \(30(30 — 1)/2 \).
Корреляция доходности акций Dow Chemical с акциями American Express такая же, как корреляция American Express с Dow Chemical, поэтому они считаются одной отчетливой корреляцией.
Необходимость в указании корреляций является отличительной чертой многомерного нормального распределения в отличии от одномерного нормального распределения.
Формулировка «предположим, что ставки доходности нормально распределены» или «предположим, что ставки доходности соответствуют нормальному распределению» иногда используется для обозначения совместного нормального распределения для нескольких ценных бумаг.
Для портфеля из 30 ценных бумаг, например, доходность портфеля представляет собой средневзвешенное значение доходности 30 ценных бумаг. Средневзвешенное значение представляет собой линейную комбинацию. Таким образом, портфель доходности нормально распределен, если доходность отдельных ценных бумаг (совместно) нормально распределена.
Напомним, что для того, чтобы указать нормальное распределение доходности портфеля, нам нужны средние значения, дисперсии, и отчетливые парные корреляции ценных бумаг портфеля.
Имея все это в виду, мы можем вернуться к нормальному распределению для одной случайной величины. Кривые на графике Рисунка 5, являются функцией плотности нормального распределения:
Доходность опционов ассиметрична. Поскольку нормальное распределение является симметричным распределением, мы должны быть осторожными в его использовании для моделирования доходности портфелей, содержащих значительные позиции по опционам.
Нормальное распределение, однако, менее подходит в качестве модели для цен на активы, чем в качестве модели для доходности активов. Нормальная случайная величина не имеет нижнего предела. Эта характеристика имеет несколько последствий для применения нормальных распределений в инвестициях. Цена актива может упасть только до 0 и в этот момент финансовый актив становится бесполезным.
В результате, на практике, финансовые аналитики, как правило, не используют нормальное распределение для моделирования распределения цен на активы. Также обратите внимание, что переход от цены актива любого уровня до 0 означает доходность -100%. Поскольку нормальное распределение распространяется ниже 0 без ограничений, оно не может быть полностью точной моделью для доходности активов.
Установив, что нормальное распределение является подходящей моделью для интересующей нас случайной величины, мы можем использовать его, чтобы сделать следующие вероятностные утверждения:
- Приблизительно 50% всех наблюдений попадают в интервал \( \mu \pm (2/3) \sigma \).
- Приблизительно 68% всех наблюдений попадают в интервал \( \mu \pm \sigma \).
- Приблизительно 95% всех наблюдений попадают в интервал \( \mu \pm 2 \sigma \).
- Приблизительно 99% всех наблюдений попадают в интервал \( \mu \pm 3 \sigma \).
Интервалы в один, два и три стандартных отклонения показаны на Рисунке 6. Эти доверительные интервалы легко запомнить, но они лишь приблизительные для указанных вероятностей. Более точные интервалы составляют \( \mu \pm 1.96\sigma \) для 95% наблюдений и \( \mu \pm 2.58\sigma \) для 99% наблюдений.
В целом, мы не наблюдаем среднее или стандартное отклонение генеральной совокупности распределения, поэтому нам нужно оценить их.
Генеральная совокупность — это все элементы указанной группы, и математическое ожидание представляет собой среднее арифметическое, рассчитанное для совокупности.
Выборка представляет собой подмножество генеральной совокупности, и выборочное среднее представляет собой среднее арифметическое для выборки.
Для получения более подробной информации об этих понятиях см. чтение о статистических концепциях и рыночной доходности.
Мы вычисляем среднее совокупности, \(\mu\), используя выборочное среднее, \( \overline X \) (иногда обозначаемое как \( \hat <\mu>\) ) и вычисляем стандартное отклонение, \(\sigma \), используя стандартное отклонение выборки, \( s \) (иногда обозначаемое как \( \hat <\sigma>\) ).
Существует столь же много различных нормальных распределений, сколько средних (\(\mu\)) и дисперсий ( \(\sigma^2 \)). Мы можем ответить на все поставленные выше вопросы с точки зрения любого нормального распределения. Электронные таблицы, например, имеют функции для расчета нормальной кумулятивной функции распределения с любыми спецификациями среднего и дисперсии.
Ради эффективности, однако, мы хотели бы свести все вероятностные утверждения к одному нормальному распределению. Стандартное нормальное распределение (нормальное распределение с \( \mu = 0 \) и \( \sigma = 1 \) ) как раз и выполняет эту роль.
Есть два шага в стандартизации случайной величины \( X \): вычесть среднее \( X \) из \( X \), а затем разделить результат на стандартное отклонение \( X \). Если у нас есть список наблюдений для нормальной случайной величины \( X \), мы вычитаем среднее из каждого наблюдения, чтобы получить список отклонений от среднего значения, а затем разделить каждое отклонение на стандартное отклонение.
Результатом является стандартная нормальная случайная величина, \( Z \) (символ \(Z \) используется по соглашению в качестве символа для стандартной нормальной случайной величины).
Если мы имеем выражение \( X \sim N(\mu, \sigma^2) \) (читается «X следует нормальному распределению с параметрами \( \mu \) и \( \sigma^2 \)» ), мы стандартизируем его, используя формулу:
Предположим, что мы имеем нормальную случайную величину, \( X \), при \( \mu = 5 \) и \( \sigma = 1.5 \). Мы стандартизируем X с помощью выражения: \( Z = (Х — 5) /1.5 \). Например, значение \( Х = 9.5 \) соответствует стандартизованному значению 3, рассчитанному как \( Z = (9.5 — 5)/1.5 = 3 \).
Вероятность того, что мы будем наблюдать значение, не превышающее 9.5 для \( X \sim N(5,1.5) \) точно такая же, как вероятность того, что мы будем наблюдать значение, не превышающее 3 для \( Z \sim N(0.1) \).
Мы можем ответить на все вопросы о вероятности \( X \), используя стандартные значения и вероятностные таблицы для Z. Как правило, мы не знаем среднее и стандартное отклонения генеральной совокупности, поэтому мы часто используем выборочное среднее \( \overline X \) для \( \mu \) и стандартное отклонение выборки \( s \) для \( \sigma \).
Стандартные нормальные вероятности также можно вычислить с помощью электронных таблиц, статистического и эконометрического программного обеспечения и языков программирования.
В Таблице 5 приведены выдержки из таблиц кумулятивной функции распределения для стандартной нормальной случайной величины. По соглашению \( N(x) \) обозначает кумулятивную функцию распределения (cdf) для стандартной нормальной случайной величины.
Другим часто использующимся обозначением cdf стандартной нормальной случайной величины является \( \Phi (х) \).
Источник