- Доходность ценных бумаг. Основные методы оценки и прогнозирования
- Какие бумаги потенциально самые прибыльные
- Формулы расчёта доходности ценных бумаг
- Ожидаемая доходность ценных бумаг
- Оценка доходности на основе математического ожидания
- Оценка доходности на основе исторических данных
- CFA — Нормальное распределение вероятностей
Доходность ценных бумаг. Основные методы оценки и прогнозирования

Ни для кого не секрет, что основной целью инвестиций в ценные бумаги является получение максимально возможной прибыли при сохранении приемлемого уровня риска. В этой статье я расскажу вам о том, какие виды ценных бумаг обладают потенциально большим потенциалом доходности. Вы узнаете о том из чего складывается их доходность и каким образом она вычисляется. Наконец, мы с вами подробно поговорим о том, как можно провести предварительную оценку и рассчитать ожидаемую доходность ценных бумаг ещё на этапе их выбора.
Какие бумаги потенциально самые прибыльные
Ответ на этот вопрос довольно прост: самый большой потенциал в плане прибыли имеют ценные бумаги с таким же большим уровнем риска. Чем выше риск, который готов взять на себя инвестор, тем выше тот доход, который он может в итоге получить. Ключевое слово в данном случае – «может», поскольку с увеличением степени риска вероятность получения дохода постепенно тает.
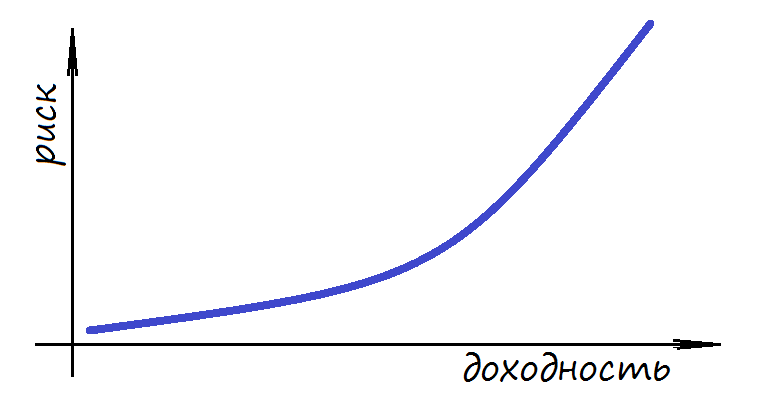
Соотношение риска и доходности
То есть, другими словами, увеличивая степень риска инвестор одновременно и повышает свою потенциальную доходность, и снижает вероятность её получения. Поэтому в инвестициях так важно найти ту самую золотую середину, тот уровень риска при котором можно рассчитывать на относительно высокую прибыль с достаточно большой вероятностью её получения.
Минимальным риском, но и наименьшей степенью доходности отличаются такие бумаги, как государственные облигации. Обычно процент по ним сопоставим с доходностью банковских депозитов и едва превышает текущий уровень инфляции. Инвестирование в бумаги данного типа целесообразно в тех случаях, когда основной целью является не приумножение, а сохранение своих денежных средств.
На ступеньку выше стоят корпоративные облигации крупнейших компаний. Они также обладают достаточной степенью надёжности, но позволяют получить чуть большую прибыль (в отличие от бумаг выпущенных государством). Ещё выше по доходности – акции тех же самых компаний, но и риск по ним тоже чуть выше. Облигация по природе своей — долговая ценная бумага, то есть она подразумевает возврат долга и процентов по нему в любом случае. А вот акция — бумага долевая. Она даёт своему владельцу долю в бизнесе компании её выпустившей, но вместе с этим он принимает на себя и определённые риски (в частности, убытки в результате возможного снижения курса акций).
Ещё более рисковыми, но и потенциально более доходными являются акции и облигации выпущенные не столь известными и не столь крупными компаниями. При этом, чем менее известна компания, тем большую прибыль она вынуждена обещать по своим облигациям (иначе никто не захочет их покупать) и тем сильнее могут в итоге «выстрелить» её акции. Ведь согласитесь, что у автосервиса за углом вашего дома, потенциал к возможному росту куда выше чем, например, у Газпрома или Сбербанка. Автосервис может увеличиться в тысячи раз развивая свой бизнес в сеть по всему городу, по всей стране или, в конце концов, даже по всему миру (вовсе не обязательно что он это сделает, но, тем не менее, теоретическая возможность этого ведь существует). А вот Газпром это уже и так достаточно крупная организация и вряд ли он сможет увеличить свою рыночную капитализацию даже в 5-10 раз.
Есть ещё такие бумаги как фьючерсные и опционные контракты. Торговля ими осуществляется с использованием кредитного плеча (левериджа) и, соответственно, размер потенциальной прибыли в данном случае гораздо выше, он прямо пропорционален размеру предоставляемого плеча. Аналогичным образом растёт и риск.
Предположим, что вы решили приобрести фьючерс на акции IBM. Спецификация данного фьючерсного контракта подразумевает его торговлю с размером левериджа 1 к 10. То есть, при цене одной акции в 135 долларов, обладая суммой в 1350$, вы можете приобрести не десять, а сто таких акций. Хотя если говорить точнее, в данном случае вы приобретёте не сами акции IBM, а фьючерсный контракт на их покупку. Но сути дела это сильно не меняет, ведь по истечении срока данного контракта вы сможете получить прибыль равнозначную той, которая была бы у вас при продаже этих самых акций. Правда при этом и возможный убыток будет равен тому, который вам принесло бы обладание 100 акциями IBM в случае снижения их курсовой стоимости.
Формулы расчёта доходности ценных бумаг
Вообще, доходность по ценным бумагам может складываться из следующих величин:
- Спекулятивный доход получаемый в результате реализации курсовой разницы при покупке и продаже ценных бумаг;
- Доход получаемый в виде дивидендов по акциям или в виде процентов по облигациям (купонный доход).
Кроме этого можно говорить о фактической и ожидаемой доходности инвестиций. Фактическая доходность отражает ту величину прибыли, которая была получена, что называется, постфактум. А ожидаемая — показывает ту её величину, которую можно будет получить в будущем.
Про ожидаемую доходность мы поговорим в следующем разделе, а сейчас давайте рассмотрим как рассчитывается фактическая доходность инвестиций в ценные бумаги.
Если речь идёт о чисто спекулятивной доходности (от разницы курсовой стоимости), то её легко можно рассчитать по формуле:
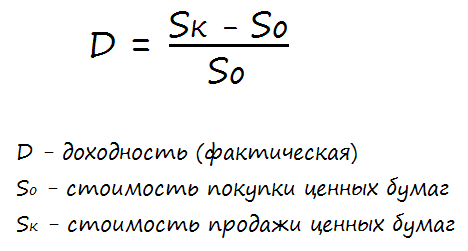
В том случае, если помимо курсовой разницы были получены ещё проценты или дивиденды, доход рассчитывается по формуле:

Обычно доходность рассчитывается в процентах годовых. Для того чтобы привести рассчитанные по вышеприведённым формулам результаты к годовой доходности, следует воспользоваться этой зависимостью:

Ожидаемая доходность ценных бумаг
Грамотное инвестирование в ценные бумаги, предполагает вероятностную оценку рисков и возможностей, выбор допускаемого значения риска и сопоставимого с ним потенциального уровня доходности**. Об инвестиционных рисках и о способах их минимизации мы говорили с вами здесь. А сейчас я расскажу вам о том, как оценить потенциальную доходность ценных бумаг.
Оценить ожидаемую доходность (ОД) можно двумя различными методами. Первый метод основан на вероятностях (математическом ожидании), а второй — на исторических данных. Давайте начнём с вероятностного метода оценки.
** Как мы уже говорили с вами выше, риск и доходность ценных бумаг находятся в прямо пропорциональной зависимости друг от друга. Чем выше риск, тем выше потенциальный уровень доходности и наоборот. Такое положение вещей обусловлено тем, что рынок сам устанавливает данное соотношение, ведь никто не хочет покупать высокорисковые бумаги с небольшим уровнем доходности.
Оценка доходности на основе математического ожидания
В данном случае учитываются все возможные варианты размера предполагаемой доходности вкупе с их вероятностью. Причём наибольший вес придаётся тем значениям, вероятность получения которых выше.
Расчёт производится по формуле:

Для наглядности вычислений, давайте приведём простой пример. Допустим перед инвестором встал выбор из двух бумаг со следующим распределением вероятностей прибылей по ним:
- Бумага А предположительно принесёт доходность в 10% с вероятностью в 50%, доходность в 7% с вероятностью в 30% или доходность в 4% с вероятностью в 20%;
- Бумага Б. Вероятность доходности в 12% составляет 30%, вероятность доходности в 8% составляет 35% и вероятность доходности в 5% составляет 35%.
Сначала рассчитываем ожидаемую доходность для бумаги А:
ОД = (0,1*0,5) + (0,07*0,3) + (0,04*0,2) = 0,079 = 7,9%
А теперь рассчитаем ожидаемую доходность для бумаги Б:
ОД = (0,12*0,3) + (0,08*0,35) + (0,05*0,35) = 0,081 = 8,1%
Очевидно, что фактическое значение доходности, скорее всего, будет несколько отличаться от рассчитанного по вышеприведённой формуле. Оценить разброс значений фактических, относительно значений расчётных, можно рассчитав величину дисперсии.
Дисперсия рассчитывается по формуле:

Для нашего примера получим дисперсию для бумаги А:
0,5(0,1 — 0,079) 2 + 0,3(0,07 — 0,079) 2 + 0,2(0,04 — 0,079) 2 = 0,000549
И дисперсию для бумаги Б:
0,3(0,12 — 0,081) 2 + 0,35(0,08 — 0,081) 2 + 0,35(0,05 — 0,081) 2 = 0,000793
Дисперсия показывает тот уровень риска, который повлечёт за собой инвестирование в бумагу для которой была рассчитана ожидаемая доходность на основе вероятностей (математического ожидания). Чем больше дисперсия, тем больше возможное отклонение фактического значения ОД от расчётного.
В нашем примере дисперсия для бумаги Б несколько выше аналогичного показателя для бумаги А. Однако, разница между ними совсем незначительная (не на порядок), поэтому можно считать, что риски рассматриваемых бумаг примерно равны. Следовательно, при прочих равных, инвестирование в бумагу Б является предпочтительным.
Оценка доходности на основе исторических данных
Как вы понимаете, не всегда есть возможность объективно оценить вероятности получения того или иного размера прибыли. Поэтому, на практике часто используют второй метод оценки ОД. Для второго способа расчёта ОД предполагается наличие данных по доходности за несколько равных временных периодов (например, за несколько лет).
Расчёт производится по следующей формуле:
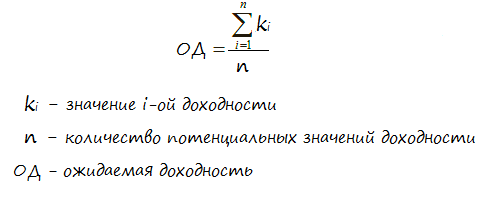
Для примера, давайте опять сравним акции двух компаний А и Б. Для простоты примера возьмём статистику годовой доходности за три последних года. Пускай акции компании А приносили доход в размере:
- Первый год — 10%;
- Второй год — 8%;
- Трети год — 15%.
А акции компании Б:
- Первый год — 5%;
- Второй год — 15%;
- Третий год — 10%.
Подставляя эти значения в формулу получим, для акций компании А:
Для акций компании Б:
Как видите, согласно расчёту, акции компании Б оказываются чуть более выгодными. Однако следует иметь ввиду, что значения доходности в прошлом, не гарантируют её в будущем. Так, в данном примере, на третий год произошло некоторое снижение прибыли. Это может быть вызвано как временными, но преодолимыми трудностями (вызванными, например, изменением конъюнктуры на рынках сбыта), так и свидетельствовать о более серьёзных проблемах компании (наличие которых, скорее всего, повлечёт за собой дальнейшее снижение прибыльности её бумаг).
Источник
CFA — Нормальное распределение вероятностей
Нормальное распределение — это наиболее часто используемое распределение вероятностей в количественной финансовой практике. Оно играет ключевую роль в современной портфельной теории и ряде технологий управления рисками. Рассмотрим эту концепцию в рамках изучения количественных методов по программе CFA.
Поскольку нормальное распределение вероятностей имеет так много применений, профессионалы в области финансов и инвестиций должны тщательно его изучить.
Роль нормального распределения в статистических выводах и регрессионном анализе значительно расширена благодаря центральной предельной теореме. Центральная предельная теорема (англ. ‘central limit theorem’) утверждает, что сумма (и среднее) большого числа независимых случайных величин приблизительно нормально распределена.
Французский математик Абрахам Де Муавр (Abraham de Moivre, 1667-1754) ввел понятие нормального распределения в 1733 году при разработке своей версии центральной предельной теоремы.
Как показано на Рисунке 5, нормальное распределение является симметричным и имеет колоколообразную форму.
Диапазоном возможных исходов нормального распределения является вся вещественная ось: все действительные числа, лежащих между \(-\infty\) и \(+\infty\). Хвосты колоколообразной кривой распространяются без ограничений слева и справа.
Определяющими характеристиками нормального распределения являются:
Нормальное распределение полностью описывается двумя параметрами — ее средним значением, \( \mu \), и дисперсией, \( \sigma^2 \). Обозначим это как \( X \sim N (\mu, \sigma^2) \) (читается «X имеет нормальное распределение со средним \(p\) и дисперсией \(\sigma^2\)» ).
Мы также можем определить нормальное распределение с точки зрения среднего и стандартного отклонения, \( \sigma \) (часто это удобно, так как \( \sigma \) измеряется в тех же единицах, что и \(X\) и \(\mu\)). Как следствие, мы можем ответить на любой вопрос о вероятности нормальной случайной величины, если мы знаем его среднее значение и дисперсию (или стандартное отклонение).
Нормальное распределение имеет асимметрию 0 (симметрично). Нормальное распределение имеет эксцесс (мера крутизны или островершинности распределения) 3; его избыточный эксцесс (эксцесс — 3.0) равен 0.
Если мы имеем выборку размера \(n\) из нормального распределения, мы хотим знать о возможном изменении в асимметрии и эксцессе выборки. Для нормальной случайной величины, стандартное отклонение ассиметрии выборки равно \(6/n\), стандартное отклонение эксцесса выборки равно \( 24/n \).
Как следствие симметрии, среднее, медиана и мода равны для нормальной случайной величины.
Линейная комбинация двух или более нормальных случайных величин также распределена нормально.
Перечисленное выше касается только одной переменной величины или одномерного нормального распределения: распределения одной нормальной случайной величины. Одномерное распределение (англ. ‘univariate distribution’) описывает одну случайную величину.
Многомерное распределение (англ. ‘multivariate distribution’) определяет вероятности для группы связанных случайных величин. Вы столкнетесь с многомерным нормальным распределением (англ. ‘multivariate normal distribution’) в инвестиционной деятельности и должны знать о нем следующее.
Когда мы имеем группу финансовых активов, мы можем моделировать распределение доходности для каждого актива в отдельности, или распределение доходности для активов как для группы. «Как для группы» означает, что мы принимаем во внимание всех статистических взаимосвязей между доходностью активов.
Одна из моделей, которая часто используется для оценки доходности ценных бумаг, является многомерным нормальным распределением. Многомерное нормальное распределение для доходности ценных бумаг полностью определяется этими тремя списками параметров:
- списком средних ставок доходности по отдельным ценным бумагам (всего \(n\) средних всего);
- списком дисперсий доходности ценных бумаг (всего \(n\) дисперсий); а также
- списком всех отчетливых попарных корреляций доходности (всего \(n (n — 1) / 2\) различных корреляций).
Например, распределение для двух акций (двумерное нормальное распределение) имеет 2 средние, 2 дисперсии и 1 корреляцию: \( 2 (2 — 1) / 2\).
Распределение для 30 акций имеет 30 средних, 30 дисперсий и 435 различных корреляций: \(30(30 — 1)/2 \).
Корреляция доходности акций Dow Chemical с акциями American Express такая же, как корреляция American Express с Dow Chemical, поэтому они считаются одной отчетливой корреляцией.
Необходимость в указании корреляций является отличительной чертой многомерного нормального распределения в отличии от одномерного нормального распределения.
Формулировка «предположим, что ставки доходности нормально распределены» или «предположим, что ставки доходности соответствуют нормальному распределению» иногда используется для обозначения совместного нормального распределения для нескольких ценных бумаг.
Для портфеля из 30 ценных бумаг, например, доходность портфеля представляет собой средневзвешенное значение доходности 30 ценных бумаг. Средневзвешенное значение представляет собой линейную комбинацию. Таким образом, портфель доходности нормально распределен, если доходность отдельных ценных бумаг (совместно) нормально распределена.
Напомним, что для того, чтобы указать нормальное распределение доходности портфеля, нам нужны средние значения, дисперсии, и отчетливые парные корреляции ценных бумаг портфеля.
Имея все это в виду, мы можем вернуться к нормальному распределению для одной случайной величины. Кривые на графике Рисунка 5, являются функцией плотности нормального распределения:
Доходность опционов ассиметрична. Поскольку нормальное распределение является симметричным распределением, мы должны быть осторожными в его использовании для моделирования доходности портфелей, содержащих значительные позиции по опционам.
Нормальное распределение, однако, менее подходит в качестве модели для цен на активы, чем в качестве модели для доходности активов. Нормальная случайная величина не имеет нижнего предела. Эта характеристика имеет несколько последствий для применения нормальных распределений в инвестициях. Цена актива может упасть только до 0 и в этот момент финансовый актив становится бесполезным.
В результате, на практике, финансовые аналитики, как правило, не используют нормальное распределение для моделирования распределения цен на активы. Также обратите внимание, что переход от цены актива любого уровня до 0 означает доходность -100%. Поскольку нормальное распределение распространяется ниже 0 без ограничений, оно не может быть полностью точной моделью для доходности активов.
Установив, что нормальное распределение является подходящей моделью для интересующей нас случайной величины, мы можем использовать его, чтобы сделать следующие вероятностные утверждения:
- Приблизительно 50% всех наблюдений попадают в интервал \( \mu \pm (2/3) \sigma \).
- Приблизительно 68% всех наблюдений попадают в интервал \( \mu \pm \sigma \).
- Приблизительно 95% всех наблюдений попадают в интервал \( \mu \pm 2 \sigma \).
- Приблизительно 99% всех наблюдений попадают в интервал \( \mu \pm 3 \sigma \).
Интервалы в один, два и три стандартных отклонения показаны на Рисунке 6. Эти доверительные интервалы легко запомнить, но они лишь приблизительные для указанных вероятностей. Более точные интервалы составляют \( \mu \pm 1.96\sigma \) для 95% наблюдений и \( \mu \pm 2.58\sigma \) для 99% наблюдений.
В целом, мы не наблюдаем среднее или стандартное отклонение генеральной совокупности распределения, поэтому нам нужно оценить их.
Генеральная совокупность — это все элементы указанной группы, и математическое ожидание представляет собой среднее арифметическое, рассчитанное для совокупности.
Выборка представляет собой подмножество генеральной совокупности, и выборочное среднее представляет собой среднее арифметическое для выборки.
Для получения более подробной информации об этих понятиях см. чтение о статистических концепциях и рыночной доходности.
Мы вычисляем среднее совокупности, \(\mu\), используя выборочное среднее, \( \overline X \) (иногда обозначаемое как \( \hat <\mu>\) ) и вычисляем стандартное отклонение, \(\sigma \), используя стандартное отклонение выборки, \( s \) (иногда обозначаемое как \( \hat <\sigma>\) ).
Существует столь же много различных нормальных распределений, сколько средних (\(\mu\)) и дисперсий ( \(\sigma^2 \)). Мы можем ответить на все поставленные выше вопросы с точки зрения любого нормального распределения. Электронные таблицы, например, имеют функции для расчета нормальной кумулятивной функции распределения с любыми спецификациями среднего и дисперсии.
Ради эффективности, однако, мы хотели бы свести все вероятностные утверждения к одному нормальному распределению. Стандартное нормальное распределение (нормальное распределение с \( \mu = 0 \) и \( \sigma = 1 \) ) как раз и выполняет эту роль.
Есть два шага в стандартизации случайной величины \( X \): вычесть среднее \( X \) из \( X \), а затем разделить результат на стандартное отклонение \( X \). Если у нас есть список наблюдений для нормальной случайной величины \( X \), мы вычитаем среднее из каждого наблюдения, чтобы получить список отклонений от среднего значения, а затем разделить каждое отклонение на стандартное отклонение.
Результатом является стандартная нормальная случайная величина, \( Z \) (символ \(Z \) используется по соглашению в качестве символа для стандартной нормальной случайной величины).
Если мы имеем выражение \( X \sim N(\mu, \sigma^2) \) (читается «X следует нормальному распределению с параметрами \( \mu \) и \( \sigma^2 \)» ), мы стандартизируем его, используя формулу:
Предположим, что мы имеем нормальную случайную величину, \( X \), при \( \mu = 5 \) и \( \sigma = 1.5 \). Мы стандартизируем X с помощью выражения: \( Z = (Х — 5) /1.5 \). Например, значение \( Х = 9.5 \) соответствует стандартизованному значению 3, рассчитанному как \( Z = (9.5 — 5)/1.5 = 3 \).
Вероятность того, что мы будем наблюдать значение, не превышающее 9.5 для \( X \sim N(5,1.5) \) точно такая же, как вероятность того, что мы будем наблюдать значение, не превышающее 3 для \( Z \sim N(0.1) \).
Мы можем ответить на все вопросы о вероятности \( X \), используя стандартные значения и вероятностные таблицы для Z. Как правило, мы не знаем среднее и стандартное отклонения генеральной совокупности, поэтому мы часто используем выборочное среднее \( \overline X \) для \( \mu \) и стандартное отклонение выборки \( s \) для \( \sigma \).
Стандартные нормальные вероятности также можно вычислить с помощью электронных таблиц, статистического и эконометрического программного обеспечения и языков программирования.
В Таблице 5 приведены выдержки из таблиц кумулятивной функции распределения для стандартной нормальной случайной величины. По соглашению \( N(x) \) обозначает кумулятивную функцию распределения (cdf) для стандартной нормальной случайной величины.
Другим часто использующимся обозначением cdf стандартной нормальной случайной величины является \( \Phi (х) \).
Источник