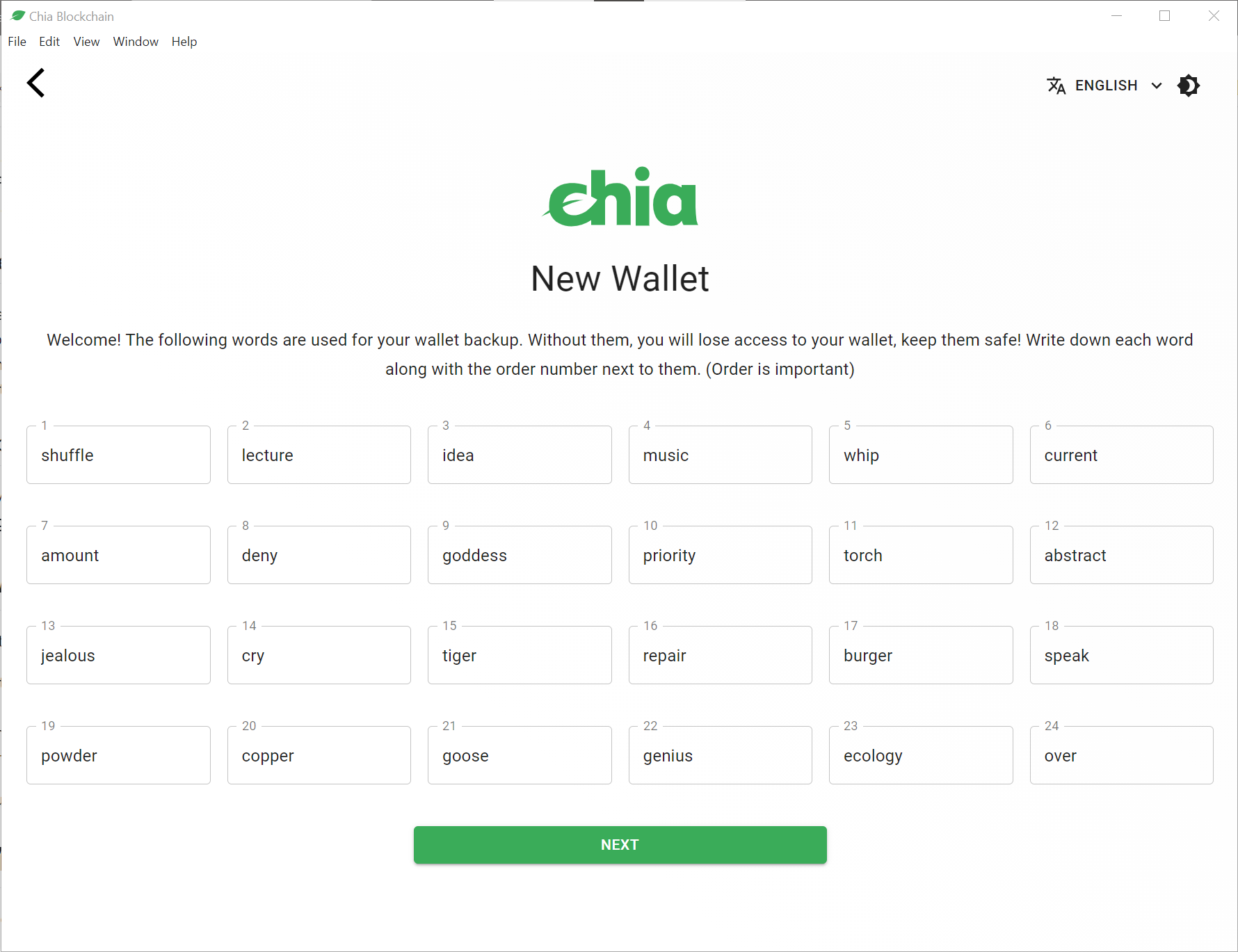
Про майнинг CHIA
dddmmm
Свой человек
Starting plotting progress into temporary dirs: E:\tmp and E:\tmp
Plot size is: 32
Buffer size is: 3390MiB
Using 128 buckets
Using 2 threads of stripe size 65536
Starting phase 1/4: Forward Propagation into tmp files. Sat May 1 14:40:46 2021
Computing table 1
F1 complete, time: 114.61 seconds. CPU (166.51%) Sat May 1 14:42:40 2021
Computing table 2
Caught plotting error: bad allocation
[3360] Failed to execute script chia
Traceback (most recent call last):
File «chia\cmds\chia.py», line 81, in
File «chia\cmds\chia.py», line 77, in main
File «click\core.py», line 829, in __call__
File «click\core.py», line 782, in main
File «click\core.py», line 1259, in invoke
File «click\core.py», line 1259, in invoke
File «click\core.py», line 1066, in invoke
File «click\core.py», line 610, in invoke
File «click\decorators.py», line 21, in new_func
File «chia\cmds\plots.py», line 135, in create_cmd
File «chia\plotting\create_plots.py», line 176, in create_plots
RuntimeError: bad allocation
ITuranchoks
Свой человек
Артем Михалыч
Новичок
Артем Михалыч
Новичок
Starting plotting progress into temporary dirs: E:\tmp and E:\tmp
Plot size is: 32
Buffer size is: 3390MiB
Using 128 buckets
Using 2 threads of stripe size 65536
Starting phase 1/4: Forward Propagation into tmp files. Sat May 1 14:40:46 2021
Computing table 1
F1 complete, time: 114.61 seconds. CPU (166.51%) Sat May 1 14:42:40 2021
Computing table 2
Caught plotting error: bad allocation
[3360] Failed to execute script chia
Traceback (most recent call last):
File «chia\cmds\chia.py», line 81, in
File «chia\cmds\chia.py», line 77, in main
File «click\core.py», line 829, in __call__
File «click\core.py», line 782, in main
File «click\core.py», line 1259, in invoke
File «click\core.py», line 1259, in invoke
File «click\core.py», line 1066, in invoke
File «click\core.py», line 610, in invoke
File «click\decorators.py», line 21, in new_func
File «chia\cmds\plots.py», line 135, in create_cmd
File «chia\plotting\create_plots.py», line 176, in create_plots
RuntimeError: bad allocation
Mr_Drakowa
Новичок

Свой человек
Мне кажется пацаны, что вы зря своё время тратите.
Не стоит засеивать кучу хардов и топить много ссд. Засейте 5-6 Тб и понаблюдайте за развитием событий.
Пока очень спешно бегать в магаз и тарить харды с ссд.
Лучше если бабки есть видики прикупить хоть 1070 теже. чем ссд nvme
dddmmm
Свой человек
takatim
Свой человек
Starting plotting progress into temporary dirs: E:\tmp and E:\tmp
Plot size is: 32
Buffer size is: 3390MiB
Using 128 buckets
Using 2 threads of stripe size 65536
Starting phase 1/4: Forward Propagation into tmp files. Sat May 1 14:40:46 2021
Computing table 1
F1 complete, time: 114.61 seconds. CPU (166.51%) Sat May 1 14:42:40 2021
Computing table 2
Caught plotting error: bad allocation
[3360] Failed to execute script chia
Traceback (most recent call last):
File «chia\cmds\chia.py», line 81, in
File «chia\cmds\chia.py», line 77, in main
File «click\core.py», line 829, in __call__
File «click\core.py», line 782, in main
File «click\core.py», line 1259, in invoke
File «click\core.py», line 1259, in invoke
File «click\core.py», line 1066, in invoke
File «click\core.py», line 610, in invoke
File «click\decorators.py», line 21, in new_func
File «chia\cmds\plots.py», line 135, in create_cmd
File «chia\plotting\create_plots.py», line 176, in create_plots
RuntimeError: bad allocation
takatim
Свой человек
aisais
Знающий
Если кто сталкивался, подскажите пожалуйста.
Сделал 1 фермера и 3 комбайна к нему по этой инструкции:
У меня на фермере не отображаются плоты, наплоченные на комбайнах, хотя в статусе фермера показывает что комбайны подключены. Так и должно быть что ли? какой смысл тогда в этих фермерах-комбайнах, проще тогда фармить на фермерах с одинаковым кошельком, или вообще наплоттив на фермерах с одинаковым кошельком перенести плотты в другую папку, затем расшарить ее и по сетке подключить на основной комп (фермер). Вот так показывает у меня комбайны в фермере, первый скрин.
В самих комбайнах тоже не все понятной, если это все делается для того чтобы не держать на комбайне полную ноду то почему он не показывает подключение к фермеру? Показывает что он сам себе полная нода, второй скрин.
В общем, подскажите, или я что то не так делаю или все так и должно быть?
ЗЫ. и еще, если на фермерах с одинаковым кошельком наделать плотты и потом скопировать друг другу, то что будет?
Источник
Скрипт для быстрого плотинга и другие полезные скрипты для майнинга Чиа 1.0
maniac84
Новичок
Доброй ночи
У меня в машите три диска SSD M.2 по 1 Тб. Я пытаюсь создать 9 потоков (по 3 на диск), но после запуска пятого на шестом и далее вылазит ошибка ошибка:
Starting phase 1/4: Forward Propagation into tmp files. Tue May 4 02:07:06 2021
Computing table 1
F1 complete, time: 144.09 seconds. CPU (186.33%) Tue May 4 02:09:30 2021
Computing table 2
Caught plotting error: bad allocation
Traceback (most recent call last):
File «chia\cmds\chia.py», line 81, in
File «chia\cmds\chia.py», line 77, in main
File «click\core.py», line 829, in call
File «click\core.py», line 782, in main
File «click\core.py», line 1259, in invoke
File «click\core.py», line 1259, in invoke
File «click\core.py», line 1066, in invoke
File «click\core.py», line 610, in invoke
File «click\decorators.py», line 21, in new_func
File «chia\cmds\plots.py», line 135, in create_cmd
File «chia\plotting\create_plots.py», line 176, in create_plots
RuntimeError: bad allocation
[8360] Failed to execute script chia
press enter to exit:
Что можно сделать?
тоже самое. Как-то решили проблему?
у меня 3 компа для создания плотов.
на первом 2 ссд по 1Тб. Для него запускают 6 скриптов (3 на один ссд, 3 на второй). 3 скрипта на первом ссд работают норм, 1 скрипт для второго ссд работает норм, а 2 и 3 скрипты для второго ссд постоянно после первой фазы вылетает вот такая же ошибка как у человека выше. Что может быть не так то скрипты же тупо скопированы, всё одинаково. Проц ксеон 12 ядер 24 потока, озу 32Гб, Через графическую оболочку программы всё норм делается 6 плотов. Посмотрел видео, думал ура сейчас ускорю себе процесс, отменил создание плотов через обычную программу, а в итоге какой-то гемор один и читаю тут у многих ошибки со скриптами. Давид, вы с Солёным хоть бы не говорили в видео, что скрипты это прям лучше гораздо. уже пол дня потратил впустую.
Plot size is: 32
Buffer size is: 5000MiB
Using 128 buckets
Using 2 threads of stripe size 65536
Источник
Chia computing table 1

Для того чтобы создать безопасный алгоритм консенсуса блокчейна с использованием дискового пространства. Необходима схема Proof of Space is. Этот документ описывает практическую конструкцию Доказательств пространства. Основанную на компромиссах Времени и памяти За пределами Хеллмана с приложениями к Доказательствам пространства [1]. Мы используем методы. Изложенные в этой статье. Расширяем его от 2 до 7 таблиц и настраиваем его. Чтобы сделать его эффективным и безопасным. Для использования в блокчейне Chia. Документ разделен на три основных раздела: Что (математическое определение доказательства пространства),
Как (как реализовать доказательство пространства) и почему разделы (мотивация и объяснение конструкции). Сначала можно прочитать статью Beyond Hellman для получения дополнительной математической информации.
Что такое Доказательство пространства?
- $e$ — натуральный логарифм
- $\ll, \gg$-побитовые операторы сдвига влево и вправо
- $%$ — оператор модуля
- $\oplus$ обозначает побитовую операцию XOR
- Если $x \in [2^z]$ — это подразумеваемая область. Равная $x \gg (z — b)$.
- Например, $(0b100100)[2:5]$ в подразумеваемом домене $[2^6]$ равно $0b010 = 2$. Кроме того, значения по умолчанию — $a=0$ и $b=z$. Если они не указаны.

- $\mathbf
(x. Y)$ является функцией соответствия $\mathbf : [2^ . \text >$; - — это хэш-функции высокого уровня
- сортировки функция
- Семя участка-это начальное семя. Которое определяет участок и доказательства пространства
Строка Качества Доказательства
$L$ и $R$ переключаются, если $L
Для удобства обозначения у нас есть функции $f_1, f_2, \cdots f_7$ с:
Как мы реализуем Доказательство пространства?

Доказательство пространства состоит из трех алгоритмов: построенияграфика , доказательства и проверки.
Построение таблиц (Концепций)
Построение графиков-это наш термин для метода записи данных на диск таким образом. Что мы можем быстро получить 1 или более доказательств (если они существуют) для данной задачи. Сюжет относится к содержимому диска. Хотя поиск доказательств должен быть быстрым. Процесс построения графика может занять некоторое время. Так как он выполняется только один раз проверяющим.

В блокчейне Chia эти проверяющие называются фермерами, поскольку они создают и поддерживают участки. То есть фермер создает и эффективно хранит данные на диске. Для данного участка семянСначала мы обсудим общие понятия. Связанные с проблемой построения графиков.
Существует 7 таблиц. Каждая из которых содержит записи $O(2^k)$. Где $k$ — параметр пространства. Каждая таблица имеет информацию для поиска $x_i$. Которые выполняют условие соответствия этой таблицы и всех предыдущих таблиц.
Т(x_1 места, \Dots с, х Т(x_1 места, \Dots с, х
Концептуально таблицы разбиваются на последовательность

Мы также ссылаемся на левую и правую половины
Эти записи также могут быть упорядочены. Так что (относительно некоторого порядка $\sigma$):
Конечная таблица, $T_7$. Является особенной. Поскольку она не содержит информации для условия соответствия. А вместо этого хранит биты $f_7$. Которые мы будем называть конечными выходами графика. Фермер должен уметь эффективно искать конечные результаты. Используя задачу. И формат данных. Используемый для достижения этой цели. Описан в контрольныхточках .
Позиции за столом
Для каждой записи вместо записи данных $x_i$ мы ссылаемся на позицию этой записи в предыдущей таблице.

Сжатие Входных Данных
У нас есть точки (позиции в предыдущей таблице) $(j_1, j_2) \in N_t$. Которые мы хотим сжать. Поскольку $x$ всегда больше. Вы можете представить себе эти записи как случайные точки в двумерном треугольнике $N_t$ by $N_t$.
(Примечание: эти данные на самом деле не находятся в дискретном равномерном распределении (напр. никакие точки линии не повторяются). Хотя мы увидим. Что это имеет незначительный эффект.)
Предположим. Что у нас есть набор точек $K$ из дискретного равномерного распределения: $x_1, x_2, \dots, x_K$. Выбранных независимо от $[RK]$.

Здесь $R$ — это параметр
Понятно. Что из этих дельт мы можем восстановить множество точек. Мы говорим, что точки находятся в дельта — формате, если мы храним эти дельты вместо точек.
ANS — кодирование дельта-форматированных точек
Мы можем кодировать эти дельты (из точек в дискретном равномерном распределении) с помощью кодирования асимметричной числовой системы (ANS [4]). Схемы кодирования. Которая по существу без потерь и предлагает чрезвычайно быстрые скорости сжатия и декомпрессии для фиксированных распределений.

Для этого требуется. Чтобы мы знали распределение $\Delta_i$. Из математики. Относящейся к статике порядка. Можно доказать. Что pdf (функция плотности вероятности) $\delta$ не зависит от $i$ и равна:
Окурок и маленькие Дельты
Чтобы смягчить это. Мы преобразуем $\Delta_i$в форму
После этого мы можем написать непосредственно заглушки и кодировку $\delta_i$.
Мы также можем рассчитать соответствующий параметр отношения пространства к записям для текущей таблицы:
Каждый парк кодирует информацию о своих записях ($e_0, e_1, \dots$) следующим образом:
Одна из проблем этой системы заключается в том. Что очень желательно. Чтобы каждый парк начинался в фиксированном месте на диске.
Один простой способ добиться этого-выделить более чем достаточно места для хранения кодировки ANS $\delta$. Поскольку дисперсия $H(\delta)$ очень мала в процентах от общего дискового пространства парка (где $H$ представляет энтропию Шеннона). Это разумная стратегия. Поскольку потраченное впустую пространство очень мало.
Мы можем оценить вероятность того. Что парки имеют достаточно места для хранения этих записей. Рассчитав среднее и стандартное отклонение информационного содержания в целом парке:
Более сложные системы записи парков на диск могут предложить незначительные улучшения сжатия. Основанные на восстановлении конечных точек парков. Которые были объединены. Более подробное обсуждение см. в разделе Парки с переменным размером.
Таблицы контрольных точек
Повторное создание доказательства пространства для задачи. Как объяснено в разделе Доказательство, требует эффективного поиска конечного результата $f_7$ в финальной таблице. Чтобы сжать представление на диске. Мы можем хранить дельты между каждым $f_7$. Которые малы. Так как существуют приблизительно $2^k$ равномерно распределенных целых чисел размера $k$.

Мы можем эффективно кодировать эти дельты с помощью переменной схемы. Такой как кодирование Хаффмана. Для простоты мы выделяем фиксированный объем пространства для кодирования дельт для записей $param_c_1 = 10000$ и разрешаем 3 бита на дельту. Чтобы предотвратить переполнения. Сохраняя их в парках.
Однако при каждой записи $param_c_1$ значение $f_7$ будет смещаться от позиции в таблице, например, запись 10 000 может храниться в позиции 10 245, поэтому мы храним контрольную точку для каждой записи $param_c_1$ в новой таблице $C_1$.

Кроме того, поскольку эти контрольные точки не помещаются в память для большого $k$. Мы можем хранить дополнительную контрольную точку каждые записи $param_c_2$ $C_1$ в новой таблице $C_2$.
Алгоритм построения графика
Окончательный формат диска
То есть запись $Table
$f_7$ — это конечный результат функции $f_7$. Который сравнивается с задачей верификации. Значения $N$ (количество записей в таблице) вычисляются в разделе Требуемое пространство. Окончательный формат состоит из таблицы. Хранящей исходные значения $x$, 5 таблиц. Хранящих позиции в предыдущей таблице. Таблицы для конечных результатов и 3 небольших таблиц контрольных точек.

Окончательный формат диска выглядит следующим образом:
| Стол | Данные | Дисковое хранилище | Приблизительное N |
|---|---|---|---|
| Нанесенная на карту точка линии, дельтафицированная, закодированная и припаркованная | $0.798*2^k$ | ||
| Сопоставленный с точкой линии, дельтафицированный, закодированный и припаркованный | $0.801*2^k$ | ||
| Сопоставленный с точкой линии, дельтафицированный, закодированный и припаркованный | $0.807*2^k$ | ||
| Сопоставленный с точкой линии, дельтафицированный, закодированный и припаркованный | $0.823*2^k$ | ||
| Сопоставленный с точкой линии, дельтафицированный, закодированный и припаркованный
| $0.865*2^k$ | ||
| Сопоставленный с точкой линии, дельтафицированный, закодированный и припаркованный | $2^k$ | ||
| Припаркованный | $2^k$ | ||
| $f_7$ | Байтовое выровненное хранилище | ||
| $f_7$ | Байтовое выровненное хранилище | ||
| $f_7$ | Дельтафифицирован, закодирован и припаркован |

$Sort$, или sort on disk. Принимает таблицу на диске и выполняет полную сортировку по возрастанию. Начиная с указанной позиции бита.
Фаза 1: Прямое распространение

Цель фазы прямого распространения состоит в том. Чтобы вычислить все таблицы. В которых выполняются условия соответствия. И вычислить все конечные выходные данные $f_7$.
Затем $Sort$ выполняется на новой таблице. Чтобы отсортировать ее по выходу $f_i$.
Это позволяет нам эффективно проверять условие соответствия. Так как соответствующие записи будут иметь соседние $bucket_id$s. Совпадения можно найти с помощью скользящего окна. Которое считывает записи с диска по одной группе за раз. $C_3$ to $C_7$ относится к выходным данным функции сортировки для каждого n
Файл $T$ будет хранить следующие данные после фазы 1:
| Стол | Данные | Дисковое хранилище |
|---|---|---|
| $Table_1$ | $f_1, x$ | Сортировка по f_1 |
| $Table_2$ | ||
| $Table_3$ | ||
| $Table_4$ | ||
| $Table_5$ | ||
| $Table_6$ | ||
| $Table_7$ |
Указатели в фазе 1 и 2 хранятся в формате pos. Offset. Формат смещения Pos представляет собой соответствие. Сохраняя позицию $k+1$ bit и намного меньшее 9 или 10-битное смещение.
Duting фаза 1, записи близки к их соответствиям. Поэтому хранение смещения эффективно. Это изменит формат двойного указателя, в котором хранятся два битовых указателя $k$. Но используется сортировка и сжатие для уменьшения каждой записи: до размера. Гораздо более близкого к $k$.

Фаза 2: Обратное продвижение
Обратите внимание. Что после фазы 1 временного файла достаточно для создания доказательств пространства. $f_7$ можно искать. И таблицы можно проследить назад. Пока не будут достигнуты значения $x$ в $Table_1$. Однако это не является эффективным.
Цель шага обратного распространения состоит в том. Чтобы удалить данные. Которые не являются полезными для поиска доказательств. Во время этой фазы все записи. Которые не являются частью условия соответствия в следующей таблице. Отбрасываются.

Позиции в следующей таблице корректируются с учетом пропущенных записей. Выходные данные сортировки (значения$C$) также отбрасываются. Поскольку они полезны только для прямого распространения. Для более эффективной фазы сжатия каждой записи присваивается $sort_key$. Который соответствует ее положению в таблице.
Реализация этого этапа требует перебора сразу двух таблиц. Левой и правой, проверки. Какие левые записи используются в правой таблице. И отбрасывания тех. Которые не используются. Наконец, требуется сортировка по позиции. Прежде чем смотреть на правую таблицу. Поэтому можно прочитать окно в обе таблицы сразу. Локально в кэше. Без чтения случайных местоположений на диске.

Файл $T$ будет хранить следующие данные после фазы 2:
| Стол | Данные | Дисковое хранилище |
|---|---|---|
| $Table_1$ | $f_1, x$ | Сортировка по f_1 |
| $Table_2$ | ||
| $Table_3$ | ||
| $Table_4$ | ||
| $Table_5$ | ||
| $Table_6$ | ||
| $Table_7$ |
Цель фазы 3 состоит в том. Чтобы перейти от формата (pos, offset). Который требует сортировки таблиц в соответствии с их $bucket_ids$ для поиска. К формату двойного указателя. Который позволяет хранить записи более сжатым способом и сортировать по $line_point$.

В pos-формате смещения около k бит требуется для pos и 8 бит для смещения. В общей сложности около $k+8 бит на запись. В то время как в формате двойного указателя мы можем в среднем около 2 бит на запись накладных расходов.

В сжатом формате два указателя могут храниться примерно в $k+2$ битах. Используя стратегии. Описанные в разделе Сжатие входных данных.
Цель формата двойного указателя состоит в том. Чтобы хранить два $k$ битных указателя на предыдущую таблицу ($2k$ бит информации) как можно более компактно. $line_point$. Это делает позиции случайными (т. Е. они больше не сортируются по совпадениям/$bucket_id$). Затем мы берем эти $2k$ bit $line_points$ и кодируем дельты между ними. Каждая из которых будет составлять около $k$ бит. Эта фаза требует некоторой тщательной сортировки и сопоставления от старых позиций к новым позициям. Поскольку у нас не так много памяти. Как дискового пространства.
При итерации от $Table_1$ к $Table_7$ выполняется сжатие. И каждая сжатая таблица записывается в конечный файл $F$.
Файл $T$ будет хранить следующие данные после фазы 3:
| Стол | Данные | Дисковое хранилище |
|---|---|---|
| $Table_1$ | $f_1, x$ | Сортировка по f_1 |
| $Table_2$ | $sort_key, new_pos$ | Сортировка по $sort_key$ |
| $Table_3$ | $sort_key, new_pos$ | Сортировка по $sort_key$ |
| $Table_4$ | $sort_key, new_pos$ | Сортировка по $sort_key$ |
| $Table_5$ | $sort_key, new_pos$ | Сортировка по $sort_key$ |
| $Table_6$ | $sort_key, new_pos$ | Сортировка по $sort_key$ |
| $Table_7$ | $f_7, new_pos$ | Сортировка по $f_7$ |
Файл $F$ сохранит окончательный формат после фазы 3, за исключением $Table_7$ и таблиц контрольных точек.
Основными узкими местами в эталонной реализации являются поиск совпадений и сортировка по диску.
Этап 4: Контрольно-пропускные пункты
Фаза 4 включала итерацию через $T.Table_7$, запись $F.Table_7$ и сжатие $f_7$s в таблицы контрольныхточек .
Сортировка на диске
Сортировка на диске-это внешний алгоритм сортировки. Который сортирует большие объемы данных со значительно меньшим объемом памяти. Чем размер данных. На больших участках эта функция быстро становится узким местом алгоритма построения графика. Он работает путем рекурсивного деления данных на более мелкие разделы до тех пор. Пока в памяти не останется достаточно памяти для раздела. Данные группируются в разделы по первым $4$ уникальным битам сортируемых чисел. Что означает. Что данные делятся на 16 сегментов. Хотя это и непрактично. Упрощенная идея представлена ниже.
При разбиении данных все должно помещаться в память. Поэтому мы непрерывно извлекаем данные из всех 16 сегментов в память и записываем обратно из памяти в целевые сегменты.
Пусть $bucket_sizes[i]$ количество записей из раздела (bucket) $i$. $writen_per_bucket[i]$ количество записей. Записанных обратно в раздел $i$. Которые принадлежат ему. И $consumed_per_bucket[i]$ количество записей. Считанных из bucket $i$ с диска. Мы также определяем $disk_begin$ как позицию на диске первой записи. А $entry_len$ — общий размер записи. Мы предполагаем. Что $bstore$ — это эффективный способ хранения и извлечения записей в памяти. Группируя записи по их первым 4 уникальным битам (их ведру).
Алгоритм работает. Постоянно заполняя память. Считывая несколько записей из каждого ведра. А затем извлекая их из памяти и записывая в нужное место на диске. На любом шаге количество записей. Записанных обратно в ведро $i$. Должно быть меньше или равно количеству записей. Считанных из ведра $i$ (таким образом. Ни одна запись не перезаписывается). Мы также сначала пишем самые тяжелые ведра. Чтобы быстро очистить память. При пополнении памяти мы читаем из buckets в порядке возрастания $consumed_per_bucket[i] — written_per_bucket[i]$. Так как чем меньше разница. Тем меньше мы можем извлечь из памяти из bucket $i$ на следующем шаге (и это оптимизирует наихудший случай). После того, как все записи были перемещены в правильное ведро. Мы вызываем SortOnDisk для каждого ведра. Пока не сможем сортировать в памяти.
Bstore реализован в виде сцепленных связанных списков. Причем каждое ведро имеет свой собственный связанный список. Более того, пустые позиции внутри памяти также образуют свои собственные связанные списки.
Сортировка в памяти осуществляется двумя способами: quicksort (когда данные не являются случайными) или наш пользовательский алгоритм SortInMemory (когда данные являются случайными).
Пользовательский алгоритм SortInMemory похож на SortOnDisk. Так как каждая запись помещается в корзину. Основное различие заключается в том. Что мы используем в два раза больше ведер, чем количество записей, гарантируя. Что у ведер будет разреженное количество записей. А столкновения замедлят алгоритм. Поскольку мы знаем. Что данные равномерно распределены. Мы примерно знаем. Куда должна идти каждая запись. И поэтому можем сортировать за время $O(n)$.
Ведро записи задается битами от $bits_begin$ до $bits_begin+b$. Мы используем память для хранения записей в ведрах: сначала мы пытаемся поместить запись в ее положение в ведре. Если позиция свободна. Мы просто помещаем туда вход. В противном случае мы помещаем туда минимум между текущим входом и существующим входом и пытаемся разместить другой вход на одну позицию выше. Мы продолжаем делать это до тех пор. Пока не найдем пустую позицию.
Построение Графика Производительности
Алгоритм разработан с учетом локальности кэша, так что случайный поиск диска не требуется. А большой объем памяти не требуется. Алгоритм сортировки на диске будет работать лучше. Если будет выделено больше памяти.
Однако требуется несколько проходов по диску. Как в сортировках. Так и в других частях алгоритма. На медленном процессоре построение может быть привязано к процессору. Тем более что AES256 должен быть вычислен по значениям O(2^k). На более новых процессорах доступны наборы команд AES. Что делает эту часть чрезвычайно быстрой. Тем не менее, сравнения. Арифметика и выделение памяти необходимы во время построения графика. Что может привести к привязке алгоритма к ЦП. Многопоточность может быть использована для разделения работы. А также для отделения процессора от дискового ввода-вывода.
Кроме того, использование SSD-накопителя или RAM-накопителя может значительно ускорить процесс построения графика.
Во время обратного распространения каждая левая таблица имеет записи $2^k$. И записи без совпадений отбрасываются. Для $Table_6$ и $Table_7$ в каждой таблице есть записи $2^k$.
Для других таблиц $Table_t$ доля не отброшенных записей равна:
Если мы кодирования каждой строки точка дельты в Ровно K битов. Которое КПП таблицы используют незначительное пространство. И что Хеллман атаки
Общий размер временного файла $T$ будет: $$ 2^k*((k+param_EXT + k) \
- 5*(k+param_EXT + (k+1) + param_offset_size) \
- (2 + 4 + 4 + 3 + 2) * к\
- 2k + k \ = 2^k*(30k + 6param_EXT + 5param_offset_size + 5) $$
Для предложенных констант временный файл примерно в 6 раз превышает размер конечного файла.
Процесс доказательства-это процесс. С помощью которого фермер, тот. Кто хранит участок. Эффективно извлекает доказательства с диска. Учитывая проблему.
Предположим. Фермер Алиса хочет доказать верификатору Бобу. Что она использует 1 ТБ данных. Боб генерирует случайный вызов. Передает его Алисе. И если Алиса может немедленно создать действительное доказательство пространства для этого вызова и правильное $k$ на основе формулы пространства, используя алгоритм доказательства. То Боб может быть убежден. Что Алиса сохранила эти данные. (На самом деле у Алисы будет только 1 доказательство в ожидании. Поэтому Боб должен выдать больше проблем).
В случае использования блокчейна нет никакой интерактивности. Но концепция быстрого доказательства случайного вызова все еще применима.
Заказ доказательств против заказа сюжета
Это означает. Что первоначальный порядок значений $x$ в $Table_1$ потерян. Но вместо этого мы имеем новый. Детерминированный порядок. Используемый на диске. Причина этого объясняется в Качественной строке. Поэтому в конце процесса поиска доказательств доказательство должно быть преобразовано путем оценки совпадений на каждом уровне и переупорядочения. Где это необходимо.
- Найдите индекс конечной записи $c_2$. Где $target
- Найдите индекс конечной записи $c_1$. Где $target
- Считайте парк из $c_3$ на основе индекса с предыдущего шага
- Найдите все индексации. Где $f_7 = target$
- Если таких индек нет. Вернитесь []
- Для каждого доказательства рекурсивно следуйте всем указателям таблицы от $table_7$ до $table_1$ и возвращайте 64 $x$ значения.
- Для каждого доказательства переупорядочите доказательство от заказа участка к заказу доказательства
Качественный Поиск Строк
Алгоритм поиска доказательств принимает файл графика $F$. Вызов $Chall$ и возвращает список строк качества $2k$ bit.
- Выполните алгоритм поиска доказательств до шага 8
- Вычислить $qual_id \получает Chall%32$
- Следуйте указателям таблицы от $Table_6$ до $Table_1$. Для каждого бита $qual_id$, если бит равен 0, следуйте за меньшей позицией, а если бит равен 1, следуйте за большей позицией пары.
- Извлеките два значения $x$ из записи $Table_1$. $x_1$ и $x_2$, где $x_1
- Обратите внимание. Что это эквивалентно строке качества доказательства.
Проверяющий должен быть в состоянии немедленно создавать доказательства для приложений консенсуса блокчейна. Для задач, которые не имеют никаких доказательств пространства. Шаги 2-7 в поиске доказательств требуют только двух поисков диска.
Когда доказательства существуют. Требуется только 6 дополнительных поисков диска. Чтобы найти качество каждого доказательства. Если потребуется получить все доказательство целиком. То это обойдется примерно в 64 поиска на диске. Использование качества позволяет нам избежать получения полного доказательства. Пока не будет найдено хорошее качество.
формате доказательстваи что усеченный $Chall$ равен конечному выходу. При успешном доказательстве верификатор также может вычислить качественную строку. Преобразовав доказательство из порядка доказательства в строку качества доказательства порядка построения.
Объяснение конструкции (Почему)
Резюме консенсуса блокчейна
Мотивация для создания Chia proof of space construction заключается в использовании в качестве альтернативного ресурса Proof of Work блокчейна в стиле консенсуса Намакото. Космические шахтеры (также называемые фермерами) выделяют место на своих жестких дисках. Отвечают на вызовы и иногда выигрывают награды. Задачи-это случайные 256 значений. Которые возникают в результате каждого блока. В блокчейне Chia эта проблема заключается в непредсказуемом выходе проверяемой функции задержки. Которая требуется для каждого блока.
Для того чтобы такой протокол был защищен от 51% атак и других консенсусных атак, ясно. Что злоумышленник не должен быть в состоянии создать доказательство пространства для пространства $S$. Используя $A
Кроме того, фаза инициализации (построение графика) должна быть как можно более эффективной. Но фермеры не должны быть в состоянии выполнить эту фазу в пределах среднего интервала блоков.
Наконец, эффективность проверяющего. Эффективность верификатора. Размер доказательства. Неинтерактивность фазы инициализации и простота честной работы-все это проблемы. Которые должны быть приняты во внимание. И это некоторые причины многих деталей конструкции. Подробно объясненных ниже. Мы будем строить от простых идей до полного определения доказательства пространства из раздела 1.
Эта конструкция Абусалы, Алвена. Коэна, Хилко. Пьетрзака и Рейзина[1] направлена на создание простой и эффективной схемы доказательства пространства по сравнению с существующими схемами PoSpace. Основанными на гальке.
Один из простейших способов построения доказательства пространства состоит в том. Чтобы верификатор задал случайную функцию $f : [N] \to [N]$. Где $N = 2^k$. Которую проверяющий должен быстро уметь инвертировать. Идея состоит в том. Что проверяющий может предварительно вычислить эту таблицу функций. Отсортировать ее по выходным значениям и быстро инвертировать любой вызов. Заданный верификатором. Например, мы можем установить $f(x) = H(n || x)$. Где $n$ — случайный одноразовый номер. Выбранный во время инициализации. А $H$ — криптографическая хэш-функция.

Новая идея в статье состоит в том. Чтобы построить функцию $[N] \to [N]$. Которая может противостоять таким атакам. Делая функцию трудно вычисляемой в прямом направлении для выбранного входа.
Функция, которая должна быть инвертирована, — это $f(x_1) = f_2(x_1, x_2)$, где $f_2(x_1, x_2) = H(x_1 || x_2)$. Но с условием. Что $f_1(x_1) = f_1(x_2) + 1$. Где $f_1(x)$ может быть другой хэш-функцией. Получив вызов $Chall$. Испытатель должен найти $x_1$ и $x_2$. Поскольку мы не можем эффективно вычислить $f(x_1)$ для любого $x_1$ (без сохранения таблицы $f_1$). Атаки Хеллмана можно смягчить. Однако вся таблица функций $f$ все еще может быть вычислена за квазилинейное время.
Чтобы реализовать такое доказательство пространства, мы можем сначала вычислить таблицу $f_1$, отсортировать по выходу и найти все пары $(x_1, x_2)$ такие. Что $f_1(x_1) = f_1(x_2)$. Затем они могут быть сохранены на диске и отсортированы по $f_2$ output.

В то время как функция $f$ выше не может быть эффективно вычислена в прямом направлении. $f_1$ может. И поэтому некоторые временные компромиссы возможны для инверсии $f_1$. Чтобы смягчить эти атаки. Мы можем увеличить количество уровней/таблиц. $m$ в конструкции. Так что злоумышленник. Оптимизирующий только один уровень. Не получит огромного преимущества.
Даже в тех случаях. Когда злоумышленник может инвертировать $f_1$ без пробела. Полученное преимущество составляет не более $1/m$ (поскольку таблица 1 меньше из-за потерянных значений).
Недостатком увеличения числа таблиц $f$ является то. Что размер доказательства растет экспоненциально с увеличением числа таблиц. Что неудобно для распространения по сети. Время проверки растет экспоненциально. Что затрудняет синхронизацию слишком большого количества блоков. Число поисков на диске также растет экспоненциально. Что делает доказательство более медленным. И вычисление этих f-функций также становится медленнее. Здесь используется число $m=7$.
Сопоставление входных данных
Поскольку увеличение числа функций $f$ приводит к экспоненциальному росту входных размеров. Это оказывает значительное влияние на производительность даже при $m=7$. В частности. Это делает временное хранилище. Необходимое для вычисления этих таблиц. Намного больше. Чем конечный размер файла графика. Кроме того, это заставляет процесс построения графика требовать больше процессора и больше времени.
Это можно улучшить. Сопоставив левое и правое значения. Используя какую-то другую функцию. А не просто конкатенацию. Как при сопоставлении.
Размер вывода функции сортировки может быть уменьшен до $3k$ и $2k$ в последних двух таблицах. Так как атака. Которая хранит эти значения. В конечном итоге будет использовать больше места. Чем экономит.
Почему цифры $3k$ и $2k$? Допустим, мы усекли размеры до $k$ вместо $3k$ для $C_6$. Это позволило бы нам оценить $f_6$ для любого входного сигнала. Сохранив все входные данные с сохранением $2k$ на запись (которая может быть дополнительно сжата). Этого достаточно. Чтобы инициировать атаку Хеллмана. Что делает инверсию $f_6$ дешевой. Если увеличить это число до $3k$. То объем памяти. Необходимый для атаки Хеллмана на $f_6$ путем хранения входных данных. Составит $6k$. Что намного больше. Чем биты честного протокола $k$ для $Table_6$ и $k$ для $Table_7$. $2k$ и $3k$ — это конвервативные числа. Гарантирующие. Что выполнение компромиссов во временном пространстве намного дороже. Чем честное хранение. Для более поздних таблиц.
Используя очень простую функцию сопоставления, такую как $M(x_1, x_2) = True \iff x_1 + 1 = x_2$. Было бы большое количество небольших островов (около $0,14 N$ для $N$ ребер и $N$ узлов). Остров-это набор записей в таблице, $S_I$ такой, что $M(E_1, E_2) \E_1 \in S_I \in E_2 \in S_I$.
Рассмотрим график. Хранящийся в формате pos. Offset.
Недостатком этой оптимизации является то. Что она усложняет алгоритм построения и формат данных. Ее не просто реализовать. И требует больше проходов по участку. Функция сопоставления должна попытаться максимизировать размер островов. Делая эту оптимизацию как можно более незначительной.
Хотя приведенная ниже функция сопоставления и не случайна. Она добавляет больше К сожалению. Во время обратного распространения до 20% записей в таблице отбрасываются. И таким образом она больше не является графом из $N$ узлов и $N$ ребер. Экспериментально это увеличивает число островов до $0.06 N$ или $0.07 N$. И таким образом встраивание является жизнеспособной оптимизацией.
Соответствующие Функциональные Требования
Рассмотрим базовый граф таблицы: орграф. Где каждый узел является записью. А ребро существует. Если эта пара записей является совпадением.
Существует две основные мотивации для функции соответствия:
- Эффективность: Все совпадения могут быть найдены эффективно. Обычно это означает, что:
- множество совпадений для поиска квазилинейно числу записей, и
- совпадения могут быть сделаны локальными для некоторой области диска. Чтобы минимизировать поиск диска.
- Нет циклов малой длины: В базовом графе (рассматривая каждое ребро как неориентированное) циклы 4-длины не существуют. Так как циклы малой длины могут быть сжаты позже (см.: Cycles attack)
Первое требование может быть выполнено только путем сопоставления вещей близко друг к другу при некотором порядке записей.
Второе требование выполняется, требуя. Чтобы базовый граф был подмножеством некоторого наложенного графа, который не имеет циклов малой длины (поскольку любое подмножество этого графа также не будет иметь циклов малой длины).
Сосредоточившись на втором требовании. Рассмотрим для параметров $(B. C)$ узлы из $\Z \times \Z_B \times \Z_C$ и ребра в графе наложения. Заданные: $$ (i. Brightarrow (i+1, b+r. C+(2r + i%2)^2) $$
для всех $0 \leq r
Рассмотрим цикл в этом графе длиной $4$ (когда ребра считаются неориентированными). У нас должно быть $2$ передних ребра и $2$ обратных ребер.
С помощью простой программы (или путем тщательного анализа) мы можем убедиться в отсутствии 4-х циклов:
Минимальный и максимальный размеры участка
Минимальный размер участка важен для предотвращения мелющих атак. Если $k$ мал. Злоумышленник может восстановить весь сюжет за короткий промежуток времени. Чтобы доказательство пространства было действительным. Доказательство должно быть сгенерировано почти сразу. А размер участка. Который позволяет генерировать участок во время доказательства. Не должен быть возможным. Есть практические соображения по выбору минимального размера. Если есть размер участка. Если можно использовать очень дорогую установку (много памяти. Процессора и т. Д.) Для быстрой генерации участка. Это все равно может работать как действительное доказательство пространства. Так как стоимость этой атаки делает ее непрактичной.
Максимальный размер графика выбран на уровне 59, консервативный максимум даже с учетом будущих улучшений жесткого диска. По-прежнему позволяющий представлять все в 64 битах и затрудняющий инвертирование k-усеченных шифротекстов AES.
Ожидаемое количество доказательств
слабо различимым, если выполняются все следующие условия:
Кроме того, кортеж. Который не является слабо различимым. Не может быть действительным доказательством. Поскольку совпадения никогда не происходят для одной и той же левой и правой половин (т.
Использование AES256 и RRAES128
Случайная функция $f$ требуется для определения доказательств пространства из — за пределов Хеллмана. Мы также можем повторно использовать один и тот же зашифрованный текст для нескольких оценок $f(x)$.
Как написано в функциюЭто похоже на режим счетчика в $AES$. Но с открытым текстом 0 и усечением выходного сигнала до k бит.

Использование режима счетчика с несколькими выходами экономит процессорное время. А также позволяет нам оценивать $f_1$ в прямом направлении. Не храня одноразовые номера.
Обратите внимание. Что даже если ключ и открытый текст фиксированы и известны. $f_1$-это односторонняя функция. Если у нас есть вывод. Например $f_1(x)$. И мы хотим вычислить прообраз без сохранения всех шифротекстов. То это потребует значительного количества процессорного времени. Поскольку мы не знаем остального шифротекста для этого блока. Если бы $k$ было намного больше 64, стало бы практичным вернуть эти функции f.
Пользовательский режим Fx
Кроме того. Число раундов AES также может быть уменьшено до 2 (минимум таков. Что каждый входной бит оказывает влияние на каждый выходной бит).
Обратите внимание. Что входы $f_2$ to $f_7$ различаются по длине. Поэтому определение должно позволить входу быть больше. Чем один блок AES. Вместо того. Чтобы использовать что-то вроде режима CBC. Используется пользовательский режим (определенный в функции $A_t$), который позволяет кэшировать выходы AES.
Поскольку совпадения вычисляются последовательно. Если запись $E$ совпадает с 3 другими записями. И $E$ находится на правой стороне совпадения. Правая половина входов $f$ может быть идентична для 3 исполнений $f$. И поэтому выходы AES могут быть кэшированы.
Сравните это с CBC. Где при первом изменении бита он влияет на весь зашифрованный текст. И поэтому кэшированные значения больше не могут использоваться. Поскольку $E$ находится справа. Открытый текст AES для E будет справа. И CBC будет шифровать различные блоки для всех трех оценок.
Потенциальная оптимизация в эталонном коде заключается в том. Чтобы воспользоваться этим преимуществом и кэшировать значения AES там. Где это уместно.
Наконец, биты $k+param_EXT$ берутся из зашифрованного текста. И операция XOR выполняется с первым выводом из предыдущей таблицы. Для $f_7$ окончательный вывод получается после шифрования. Усечения и XORing с левым выходом $f_6$.
Причина, по которой используются только два из 64 значений доказательства. Заключается в том. Что чтение двух значений $x$ требует поиска $6$ на диске. В отличие от поиска $64$: только одна ветвь проходит через дерево. В отличие от каждой ветви. Фермер, работающий с доказательством пространства в блокчейне. Может проверять свой участок каждый раз. Когда видит новый блок или новый вызов. Однако в большинстве случаев они не выиграют блок. И их доказательство качества пространства будет недостаточно хорошим. Таким образом. Мы можем избежать 64-дисковых поисков. Необходимых для получения всего доказательства. Можно использовать два соседних значения $x$. Так как они хранятся вместе на диске. И поэтому дополнительные поиски диска не требуются по сравнению только с чтением одного.
Важно, что выбор того. Какие значения $x$ должны быть извлечены. Зависит от задачи. Если бы всегда использовались первые два значения x, злоумышленник мог бы вычислить участок фермера и сохранить $x_1, x_2$ для всех доказательств на участке и иметь возможность вычислить качества со значительно меньшим объемом памяти. Чем полный участок. Это позволило бы злоумышленнику, например. Отказаться от блоков. Которые приносят пользу другим.
Кроме того, поскольку фермер заранее не знает задачи. Качества не могут быть заранее вычислены.
В процессе построения графика входные данные сжимаются путем переупорядочения кортежей. Что означает потерю порядка значений proof $x$. Качество, которое вычисляет проверяющий (проходя назад по таблицам). Основано на этом измененном порядке. Поэтому верификатор должен выполнить это вычисление, чтобы получить эффективный порядок. Используемый проверяющим.
$plot_seed$ — это 32-байтовое значение. Которое используется для детерминированного заполнения всего участка.
Построение алгоритма локализации кэша
Поскольку графики доказательства пространства должны быть очень большими (из-за минимума $k$). Алгоритм построения графика должен требовать значительно меньше памяти. Чем дисковое пространство. Чтобы достичь этого. Поисковые таблицы размера $O(N)$ не должны быть необходимы для построения графика. А случайные точки на диске не должны часто считываться.
Это особенно важно в фазе прямого распространения. Где пары записей $E_1$ и $E_2$ должны быть сопоставлены для сопоставления. Одно из требований соответствия состоит в том. Что $bucket_id$ из $E_2$ на единицу больше. Чем $E_2$. Поэтому в фазе прямого распространения мы сортируем по выходу $bucket_id$/$f$.
На этапе сжатия позиции в предыдущих записях таблицы основаны на сортировке вывода $f$. Но для экономии места они преобразуются в позиции в таблицы на основе сортировки $line_point$. Это сопоставление не может быть выполнено с помощью таблицы поиска. Поэтому мы сначала сортируем по новым критериям сортировки. Записываем индекс каждой новой записи. А затем снова сортируем по старым критериям. Чтобы можно было перебирать следующую таблицу. Используется небольшое окно. Которое требует очень мало памяти.
Парки С Переменным Размером
Нынешняя реализация ставит участки пустого пространства между парками, что является расточительным и может быть использовано. В следующем обсуждении
В альтернативной схеме. Которая имеет
Один из способов решения этого подхода-иметь переменное количество записей на парк. В частности. Предположим. Что каждый парк (за исключением, возможно. Последнего) либо имеет записи $EPP-1$. Либо $EPP+1$. Для каждого дома нам нужно 1 дополнительный бит. Чтобы представить эту разность размеров следующего парка. А также нам нужно хранить сумму этих разностей размеров (-1 или 1). Идея заключается в том. Что когда наше выравнивание парка отрицательно. Мы делаем большие парки; а когда наше выравнивание парка положительно. Мы делаем меньшие парки.
Кроме того, со стороны нам нужен “домашний намек”. Предположим, EPP = 2048, и нам нужна 2500-я запись. Мы бы предположили, что он находится во втором парке, поскольку, грубо говоря, записи 1-2048 находятся в первом парке, 2049-4096-во втором парке и так далее. Наша идея состоит в том. Что всякий раз. Когда наше предположение окажется неверным. Мы создаем подсказку в памяти. Которая определяет интервал записей. Для которого мы должны изменить наше предположение на некоторое число. Мы можем двоично поискать эту таблицу подсказок. Прежде чем отправиться в парк.
На самом деле таблица подсказок будет очень маленькой. Так как различия в размерах должны иметь абсолютное значение. Превышающее EPP. Чтобы мы могли записать подсказку. В качестве детализации уровня реализации нам действительно нужно прочитать два соседних парка. Чтобы убедиться. Что наша таблица подсказок невелика — если мы этого не сделаем. Наша таблица подсказок будет очень большой. Так как каждое изменение знака между текущей суммой различий в размерах вызовет новую подсказку для записей вблизи границ каждого парка.
С учетом базовых графе таблицы (см. соответствующие функции требованиям), написать можно сказать, 3 из связанных записей соответствующих краев цикл 4 на диске. А также указать. Как ходить по краям цикла (возможно. Некоторые ребра шли в обратном порядке). Чтобы найти последний край (запись).
Поскольку нет 4-циклов (или 5-циклов. Поскольку каждое ребро изменяет четность первой координаты). Цикл минимальной длины является 6-циклом.
Для каждого цикла на острове в графе таблицы можно сохранить одно из ребер, указав. Как пройти по ребрам. Чтобы найти пару. А не давать аналог непосредственно. Есть два типа циклов. Которые происходят: 4-циклы. Которые происходят. Когда есть ведро. В котором есть две вещи и есть по крайней мере две вещи. С которыми оно связано, и 6-циклы. Которые могут произойти с двумя ведрами. Где две вещи в них связаны. Но более распространены как случайность через граф в целом. Циклы, зависящие от множества вещей в одном и том же сегменте. Можно сделать гораздо менее распространенными. Увеличив степень графа (и. Соответственно. Размер B-группы) за счет прямого линейного расхода процессорного времени. Длина других типов циклов может быть увеличена за счет увеличения размера С-группы за счет соответственно большего объема кэш-памяти при построении графиков.
Как упоминалось в Beyond Hellman, эта конструкция делает атаки Hellman менее мощными. Но они по-прежнему являются стоящей оптимизацией для первой таблицы.
Основная атака Хеллмана на $Table_1$ работает следующим образом: вместо хранения $k$ бит на запись для табов 1 и 2 мы ничего не храним для $Table_1$, а для $Table_2$ мы храним $x_1, x_3$ вместо $pos_l, pos_r$, которые были позициями в $Table_1$ для $x_1, x_2$ и $x_3, x_4$.
При поиске качества или доказательства мы можем оценить $f_1(x_1)$ и $f_1(x_3)$. Которые будут очень близки к $f_1(x_2)$ и $f_1(x_4)$ соответственно. Благодаря функции соответствия. Это все еще требует инверсии $f_1$. Которую мы пытаемся выполнить для каждого из 32 потенциальных значений $f_1$.
Чтобы инвертировать. Мы храним цепочки контрольных точек. Как в Радужных таблицах[2], проверяем. В какой цепочке мы находимся. И оцениваем ее.
Также могут быть коллизии и ложные срабатывания. То есть мы инвертируем $f_1$. Но получаем неверный ввод. Это можно исправить. Также проверив. Что все полученные значения $x$ также совпадают по отношению к $f_2$.
Если $Table_1$ полностью удален. То $13%$ пространства из конечного файла графика сохраняется. Что делает эту потенциально наиболее значимую оптимизацию.
Предостережение этой оптимизации заключается в том. Что для настройки радужных таблиц потенциально требуется большой объем памяти. Это связано с тем. Что алгоритм нуждается в проверке того. Включено ли каждое рассматриваемое значение $x$ уже или не включено в сохраненные цепочки. Кроме того, если не все значения $x$ будут покрыты. Вероятность успеха графика уменьшится. Чтобы охватить все значения $x$. Для доказательства требуется значительный объем памяти. Чтобы сохранить все эти оставшиеся значения x.
Потенциально. Некоторые компромиссы могут быть выполнены. Чтобы сделать атаку требующей меньше процессора и меньше памяти. Что немного снижает эффективность сюжета.
Отбрасывание битов в значениях x / точках линии
Часть сохраненных точек линии в $Table_1$ может иметь отброшенные биты $z$. И при восстановлении все возможные значения отброшенных битов могут быть грубо принудительными. Чтобы восстановить точку линии, мы находим усеченную точку линии, а затем пробуем каждую возможность для отброшенных битов, пока не найдем результирующую пару $(x_1, x_2)$, такую что $M(x_1, x_2)$ истинно. Обратите внимание. Что ложные срабатывания возможны. Но они редки и могут быть проверены путем оценки $f_2$.
Эта оптимизация. Как и атаки Хеллмана. Основана на использовании процессора для минимизации $Table_1$. Кроме того, это не кажется практичным ни для чего. Кроме $Table_1$. И, возможно. Нескольких битов из $Table_2$. Если злоумышленник попытается усечь биты $z$ из всех таблиц. Количество поисков диска становится экспоненциальным (а также требуемое вычисление).
Уменьшите накладные расходы на построение графика
На этапе прямого распространения метаданные необходимы только для вычисления следующей таблицы. После того, как следующая таблица будет вычислена. Метаданные могут быть удалены. Чтобы сэкономить место на диске.
Кроме того, для каждой пары таблиц во время прямого распространения левые записи таблицы. Которые не приводят ни к каким совпадениям. Могут быть немедленно отброшены. Хотя обратное распространение отбрасывает любую запись. Которая не приводит к совпадению $f_7$. Большинство записей могут быть отброшены при прямом распространении с использованием вышеуказанного метода.
Обе эти оптимизации экономят рабочее пространство. Но увеличивают количество проходов. Которые необходимо выполнить. Иим образом. Увеличивают размер участка. Для очень больших участков. Где время сортировки имеет большее значение. Чем количество проходов. Эти оптимизации также могут привести к более быстрому времени построения.
В большинстве случаев. Когда сортировка на диске завершена. Последний проход в памяти записывается на диск. Если есть операция, которая должна быть выполнена с отсортированной таблицей (например, во время прямого распространения), то более эффективно выполнять эту операцию во время сортировки, чтобы минимизировать поиск на диске, а не ждать. Пока будет отсортирована вся таблица.
Каждое значение pos_R используется по крайней мере один раз
Чтобы дать хорошее приближение теоретических потерь от неучета этой информации. Рассмотрим таблицу из $N$ записей. Где каждая запись независимо выбирается как указывающая на две разные позиции из $[N]$.
Пусть $e_i$ — это набор таблиц. В которых нет точек входа в $i$. Таким образом. По принципу включения-исключения,
Поэтому эта информация не может быть использована для значительного уменьшения размера участка.
Обрезка плохих значений x
Большинство записей. Хранящихся в графике. Не могут быть удалены без снижения эффективности графика на байт. Однако удаление записей. Которые приводят к немногим или только одному окончательному решению. Может привести к увеличению эффективности на байт. Это будет небольшое количество записей. Так как шансы найти несколько таких записей. Которые вносят вклад в один и тот же конечный результат. Экспоненциально уменьшаются с $Table_7$ до $Table_1$.
Некоторые участки с помощью случайного шума будут иметь большую эффективность на байт. Сумма этого пропорциональна квадратному корню из размера участка с небольшим постоянным коэффициентом. Поэтому потенциальные выгоды не высоки. Фуртермор, это требует оценки всей фазы прямой пропаганды. Если у фермера есть несколько участков. И он хочет удалить один из них. Наименее эффективный может быть восстановлен первым.
Уменьшить размер таблицы контрольных точек
Используя более эффективную кодировку для хранения дельт значений $f_7$ в таблице $C_3$. Можно сохранить теоретический максимум до 2 бит на запись (текущий размер таблицы $C_3$). Это около 1% для $k=33$.
Более быстрый диск
Построение графиков на SSD или ramdisk обеспечит значительное повышение производительности. Особенно для больших участков. Где сортировка на диске становится узким местом.
Многопоточность может значительно повысить производительность. Использование процессора на большинстве фаз полностью параселлизуемо. И блокировка дискового ввода-вывода может быть сведена к минимуму.
[1] Хамза Абусалах. Джоэл Алвен, Брэм Коэн. Данило Хилько. Кшиштоф Петрзак. Леонид Рейзин: За пределами компромиссов временной памяти Хеллмана с приложениями к доказательствам пространства (2017) https://eprint.iacr.org/2017/893.pdf
[2] Philippe Oechslin: Making a Faster Cryptanalytic Time-Memory Trade-Of (2013) https://lasec.epfl.ch/pub/lasec/doc/Oech03.pdf
[3] Krzysztof Pietrzak. Bram Cohen: Chia Greenpaper (2019)
Источник